
In the last few years, deep learning models achieved groundbreaking results on several computer vision tasks. Yet these models rely on vast amounts of carefully labeled images. The collection of the dataset images is substantially cheaper compared to the price of high-quality annotations. Alternatively, one can collect images from the internet with different tags and use these tags as labels, or crowdsource the annotation process, resulting in much cheaper yet noisier annotations. This motivates the research in directions of unsupervised learning, semi-supervised learning, learning with noisy labels, and active learning.
Active learning in computer vision
Active learning algorithms help deep learning engineers select a subset of images from a large unlabeled pool of data in such a way, that obtaining annotations of those images will result in a maximal increase of model accuracy. They tackle the question of which N images do I annotate next to get the best performing model. This is pretty helpful since in some cases labeling of the whole dataset is impossible due to time and budget constraints.
There are several promising Active Learning algorithms available, yet evaluation and benchmarking of these algorithms is not clear. Different methods use different datasets, report different metrics on different tasks. Most of the methods report results on the classification tasks only, which we are least interested in. We will benchmark these algorithms on classification, object detection, segmentation, human pose estimation, and semantic segmentation and report the mean accuracies of 3 runs for each of them. We will add more algorithm implementations over time and provide instructions for easy integration into our platform.
The current article covers classification tasks only. Further articles will be published reporting on results for object detection, segmentation, human pose estimation, and semantic segmentation tasks. We were able to get good results on all the tasks using different algorithms.
In this article, I would like to present our implementation of 2 active learning algorithms ([1], [2]) and their usage in SuperAnnotate's platform, share the code and some benchmarking data. Only classification models will be covered in the article, separate articles will follow for each subsequent task. This is the start of our continuous effort in implementing and evaluating different active learning algorithms and making them easily accessible for our users.
Outline
- Brief Description of “Learning Loss for Active Learning” algorithm [1]
- Brief Description of “Discriminative Active Learning” algorithm [2]
- Results on classification task on a cifar-10 dataset with resnet-18 model
- Using our code
- Future Roadmap
- Concluding remarks
- References
Brief description of “learning loss for active learning” algorithm
In this chapter, we will briefly describe the Learning Loss for Active Learning [1] algorithm, which we use for all 4 tasks. For a full description please refer to the paper.
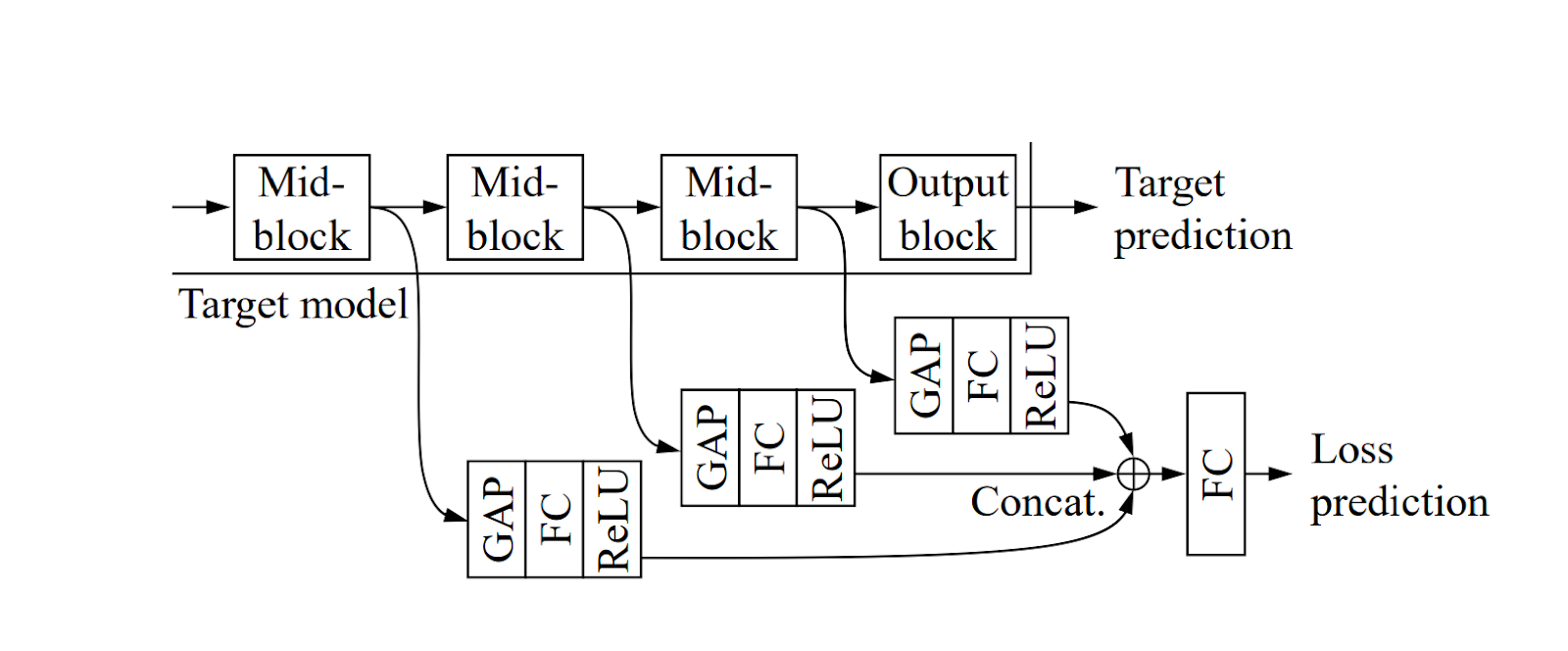
The main idea behind this algorithm is to attach a loss prediction module to the main model (Fig. 2) the task of which will be to estimate the loss for a given unlabeled image. This additional task is learned in parallel to the main task, resulting in a negligible training time increase. Fig. 3 demonstrates the architecture of these additional layers. Features of several layers of the main model are used, which pass through a Global Average Pooling, FC layer (with output width of 128), and a ReLU. All of the outputs of these layers are concatenated and pass through another FC layer, which predicts the final loss.
After training this module, a subset of the unlabeled images is passed through it, and images with the highest predicted loss are selected for labeling (assuming those will increase the main model’s accuracy the most).

Brief description of “discriminative active learning” algorithm
The main idea behind this algorithm [2] is to build a classifier, which predicts if a given image is in the labeled or unlabeled sets. Once trained, the classifier is run on a subset of unlabeled images, and images for which the classifier is most certain that they belong to the unlabeled set are selected to be labeled. The intuition behind the algorithm is that every time we select new images to label, we must keep the labeled dataset as similar to the whole dataset as possible. The chosen architecture is very simple, a multi-layered perceptron with 3 hidden layers with a width of 256 and ReLU activations.
Results on classification task on a cifar-10 dataset with resnet-18 model
Both Active Learning algorithms were evaluated for classification on the Cifar-10 dataset using the Resnet-18 model. We employed an open-source code [3]. You can see our code here. We start by selecting 1000 random labeled images (same for all the algorithms), then select another 1000 images for 10 cycles. We measure the classification accuracy and report the mean values for 3 runs with 3 different random seeds.
For loss prediction active learning we make no changes to the hyperparameters or augmentations, exactly replicating the experience described in the paper [1]. We train for 200 epochs with a mini-batch size of 128 and the initial learning rate of 0.1. After 160 epochs, we decrease the learning rate to 0.01. The momentum and the weight decay are 0.9 and 0.0005 respectively. After 120 epochs, we stop the gradient from the loss prediction module propagated to the target model.
For “discriminative active learning” [2] we make 10 mini-queries, I.E. instead of selecting 1000 images at once on each cycle, we select 100 images 10x and re-train the classifier after each selection. We train the classifier for 500 epochs but terminate the training if classification accuracy on the training set has reached 0.98. Even though a Keras implementation was provided, we re-implemented the algorithm in PyTorch which can be found here.
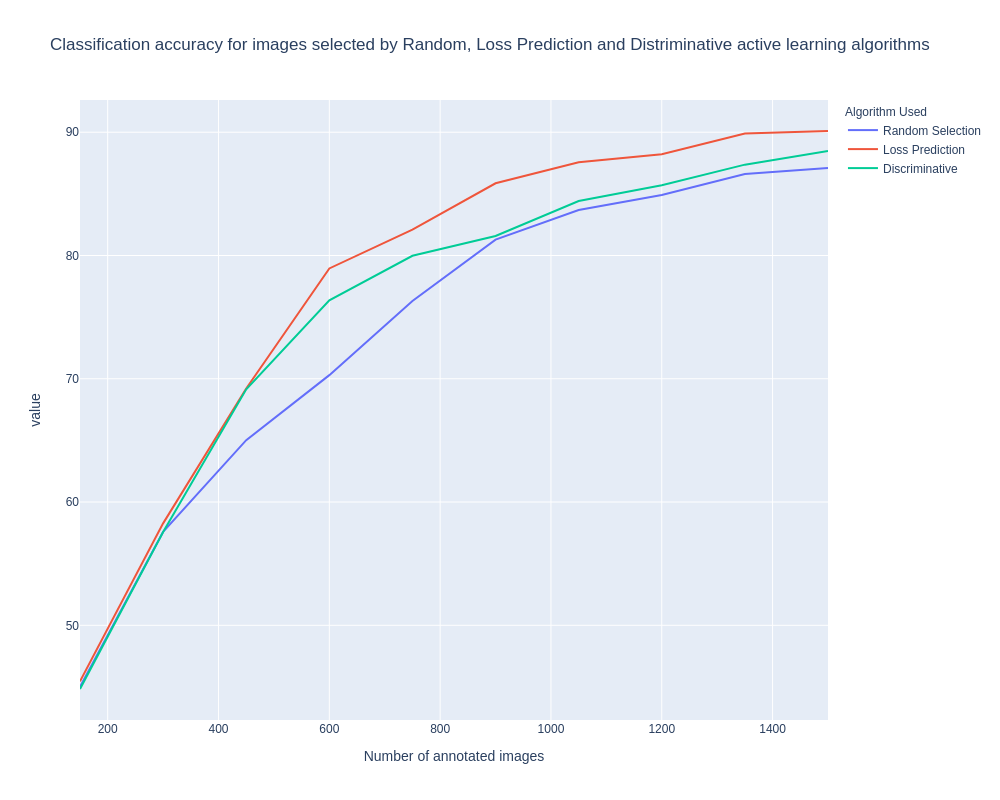
Fig. 4 provides experimental results on cifar-10. Each chart is the mean of 3 runs with different random seeds. We can see that discriminative active learning slightly outperformed random, and loss prediction algorithm outperformed random by a margin of 3%.
Using our code
Our code for all the above-mentioned algorithms and experiments can be found here. The README contains detailed instructions on how to run our code or add your active learning algorithm. It can also generate CSV files to be uploaded to SuperAnnotate's platform. This code is a work in progress and will be maintained and updated. The repo contains code copied from other open-source repositories mentioned above, please refer to the original repositories when using them.
Concluding remarks
We plan to create an open-source codebase with multiple active learning algorithm implementations, all implemented in a similar way and evaluated on the same datasets, tasks, and models. We hope to help our users select the right algorithm for their dataset and model based on this code and evaluation results, and easily integrate it in the SuperAnnotate's platform.
If you are a researcher in the active learning community and would like to add your algorithm to our repository, feel free to contact us.
Future roadmap
Further articles will be published reporting on results for object detection, segmentation, human pose estimation, and semantic segmentation tasks. We were able to get good results in all the tasks.
The following improvements are planned to be made in the near future:
- Improve loss prediction active learning performance on Human Pose estimation and segmentation tasks
- Improve performance of the discriminative active learning implementation
- Evaluate discriminative active learning on the other 3 tasks
- Create an active learning algorithm/framework for selecting frames of a video to be annotated and integrate it to SuperAnnotate platform’s video annotation feature
References
[1] Donggeun Yoo and In So Kweon. Learning Loss for Active Learning. arXiv:1905.03677 [cs.CV], May 2019.
[2] Daniel Gissin and Shai Shalev-Shwartz. Discriminative Active Learning. arXiv:1907.06347 [cs.LG], Jul 2019.
[3] Classification on cifar with resnet open-source code. https://github.com/kuangliu/pytorch-cifar






