
When talking about artificial neural networks, people often use the word learn. What do we mean when we say that a network learns things? The concept seems intuitive in the case of humans and other animals, but not so much for machines. However, machines do, in fact, learn, and it’s all based on concepts from optimization, most importantly the eponymous gradient descent algorithm. So, what is it, how does it work, and how can we use it to train neural networks? Here’s a quick rundown of what we’ll cover:
- Developing an intuition for derivatives
- Gradient descent: the how and the why
- Applying gradient descent
- Bonus: Improving gradient descent
- Sum up
Before tackling gradient descent itself, let’s get a quick refresher of the concepts one needs to know to understand the algorithm.

Developing an intuition for derivatives
Since many optimization methods, including gradient descent, rely on derivatives, it’s useful to develop an intuition for them. While many people rely only on derivative computation tricks for their understanding of the concept, it’s actually more useful to look at the formal definition and develop an intuition based on that. A derivative is defined as follows:

The keen reader may have noticed that the definition looks strangely similar to that of slopes. This is no coincidence. In fact, the simplest intuition for derivatives is that the derivative of function 𝑓 at point c tells us what the slope of 𝑓 is when approaching c. In other words, we get an answer to the question, “how sensitive is our function to tiny little changes around this point?” If the derivative at a point is positive, then the function is “going up,” and if it’s negative, it’s “going down.” We’ll see just how useful this information is in a section down the line.
Side note: This isn’t the only way to think of derivatives intuitively, albeit it’s the simplest one and the one most useful for understanding gradient descent. For an alternate (and fascinating) explanation, check out 3blue1brown’s video on the topic.
Another concept often used in optimization is the second derivative. As its name suggests, it’s simply the derivative of the derivative. Now, how do we understand this intuitively? Well, since the derivative tells us how a function changes based on small nudges to its input, and the derivative is itself a function, it’s only natural that the derivative of the derivative tells us how the derivative changes with small changes to its input. A helpful way to think of this is as follows: if the second derivative at a point is positive, then the function’s slope around that point is increasing, and if it’s negative, then it’s decreasing. Visually, this corresponds to changes in the function’s curvature: a positive second derivative corresponds to convex curvature (like a bowl), while a negative slope corresponds to concave curvature (like an umbrella).

Optimization as an algorithm for learning vs. pure optimization
Optimization in machine learning differs from the pure optimization you’d find in textbooks, and the kind practiced in economics and often statistics. The main difference lies in the fact that machine learning algorithms usually work indirectly. The reason for this is the fact that in machine learning, the goal is to optimize some performance measure P that’s defined with respect to test data (i.e., we want the model to be as good/accurate as possible on data it has never seen before). Since the algorithm doesn’t learn on test data by design, it can therefore only optimize P indirectly by optimizing the loss function.
Gradient descent: the how and the why
Now that we have a good high-level understanding of the concepts we need to know let’s try to build an intuition for gradient descent itself.
What exactly is a gradient?
Despite its fancy name, a gradient is just a bunch of partial derivatives. This means that if we have some function of multiple variables, its gradient is just a vector of the function’s derivatives with respect to each of its variables. How exactly does one compute a derivative with respect to a variable, one may think. It’s super simple, you just treat all the other variables as constants! This is also helpful in building an intuition for partial derivatives: we fix all the other variables and see how changes in this one affect the function. Once we compute the derivatives with respect to each variable, we just stack them in a vector and get the function’s gradient.
Now, here’s the best part. The gradient has a fascinating property: it points in the direction where the function grows fastest! Correspondingly, the opposite direction is where the function decreases fastest. Now, say we’ve computed the gradient of our loss function. Our loss function tells us how wrong our model’s predictions are. The lower the loss, the better our model’s predictions. So, since our goal is to minimize the loss function, the best course of action is to take a “step” in the direction where the function decreases fastest, which, as we saw, is the direction opposite to where the gradient points. This is the main intuition behind gradient descent: we use the gradient to determine which direction to descend towards.
The gradient descent algorithm
In the previous section, we talked about taking a step in the direction of the steepest descent, which is the direction opposite to the gradient. How exactly do we do that?
Keep in mind that we’re taking all the partial derivatives of our loss function. The loss function’s parameters are the weights and biases of the network (since those determine the network’s predictions and the other parts of the loss function are fixed). Thus, we’re differentiating with respect to each weight and bias. This very fact is what allows us to update the network’s weights in a meaningful way. Here’s the formula for the weight update rule:

We denote with gₜ,ⱼ the derivative of the loss function with respect to the j-th weight during time step t. In the second equation, 𝜃ₜ,ⱼ is the j-th weight of the network at time step t, while the second term of the right-hand side is the partial derivative multiplied by a constant alpha. This alpha is called the learning rate and is just a scalar by which we multiply the derivative in order to make the step a little smaller (if we take too big a step, we risk jumping over minima and thus not improving our model at all). Choosing a good learning rate is important, but it’s usually done empirically (you can generally start with something like 0.001 or 0.0001 and tweak from there). Taking all this into account, we see that the formula is essentially the following: To adjust the weight, we take the old one and subtract from it the loss function’s derivative in respect to it multiplied by the learning rate to make sure we’re actually improving the model, not just jumping around.
Applying gradient descent
As we saw in the previous section, gradient descent is a fairly simple algorithm, but we need a few tricks to actually apply it in the real world effectively.
Scaling gradient descent
The main challenge with gradient descent is the fact that if we perform it on all our data at once, it quickly becomes insanely computationally expensive, especially given the fact that neural networks are usually trained on a lot of data. One thing we can do to remedy this is to perform the computations on one example, adjust the weights and biases, and so on. This method is referred to as stochastic gradient descent. The stochasticity comes from the fact that we’re not taking a step in the exact direction of the steepest descent but rather our best guess based on one data point. This works especially well with large datasets since, by the law of large numbers, the average of the per-datapoint gradients is close to the actual one. Here’s a useful illustration of traditional and stochastic gradient descent:

Regular gradient descent takes the most direct route possible, while stochastic gradient descent may zigzag a little more but is actually usable on big datasets because of relative computational simplicity. One very commonly used trick to improve the effectiveness of stochastic gradient descent while keeping it computationally manageable is by using several examples instead of one. So, instead of computing the derivatives and updating the weights based on one example, we choose some number of examples to use. This is referred to as minibatch gradient descent or minibatch stochastic gradient descent. It is sort of a middle ground between gradient descent and stochastic gradient descent and tends to converge quite quickly while not being too computationally expensive.
Bonus: Improving gradient descent
Most modern optimizers are based on stochastic gradient descent but incorporate some additional terms and tricks to speed up convergence.
Let’s go over a few of them briefly:
- Momentum: Combined with stochastic gradient descent, momentum takes into account past gradients to smoothen the weight update and fasten convergence. This way, the algorithm moves toward the most significant directions, avoiding some of the oscillations in stochastic gradient descent. Intuitively, it can be thought of like a ball rolling downhill: it will accelerate and continue going downhill, even if there are some bumps along the way.
Formally, it is defined as follows:
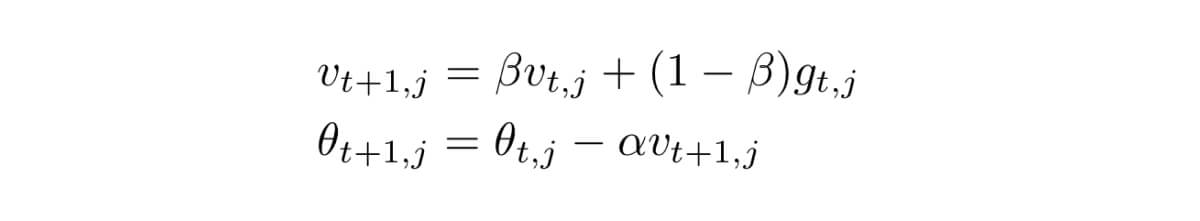
Here, beta is just a constant between 0 and 1 that decides how much importance the momentum from previous steps is given during the update. The bigger the beta, the more momentum affects the weight update. Alpha is the learning rate and gₜ,ⱼ is the gradient of the loss function, same as before.
A disadvantage of this method is the fact that beta needs to be chosen carefully to ensure convergence. Another drawback is that the accelerating momentum may cause the algorithm to jump over minima. This second one is remedied by a similar algorithm called Nesterov momentum, which uses a projection of the weight during the next step in this step’s computations.
- Adagrad (Adaptive gradients): this algorithm uses an adaptive learning rate (hence the name). It uses a lower learning rate for parameters associated with frequently occurring features and vice versa, which makes it well-suited for sparse data. Here’s the formula for the weight update:

𝜃ₜ,ⱼ is the j-th weight during time step t, η is the learning rate, and gₜ,ⱼ is the derivative of the loss function with respect to the j-th weight during time step t. The part under the square root is the interesting part. Gₜ belongs to Rᵈˣᵈ is a diagonal matrix where each diagonal element is the sum of squares of the gradients with respect to 𝜃ⱼ from 0 up to time step t. The epsilon is just a small constant that’s there to avoid zero division (it’s something like 1e-7 or 1e-8).
The main benefit of Adagrad is that it removes the need to manually tune the learning rate. The main disadvantage is that since we’re summing squared gradients, the terms in the matrix G are going to continuously increase, which eventually makes the learning rate too small to make meaningful updates.
- RMSProp (Root Mean Squared Propagation): This algorithm is somewhat unique in that it wasn’t published formally but rather proposed in a Coursera course by lecturer Geoff Hinton. It fixes the issue with Adagrad by dividing the learning rate by an exponentially decaying average of the squared gradients. It looks like this:

The term E[g²]ₜ,ⱼ is the above-mentioned decaying average that only depends on the previous average and the current gradient. Gamma is a constant between 0 and 1, similar to the one in momentum, which the author recommends be set to 0.9, with a 0.001 initial learning rate.
Note: This algorithm is similar to the independently proposed Adadelta, so I didn’t see the need to discuss both.
- Adam (Adaptive Moment Estimation): This is perhaps one of the most widely-used optimizers (combined with ones based on it like RAdam, AdamW, Ranger, etc.). The idea is to utilize exponentially decaying averages of the past gradients and the squared past gradients. It’s done similarly to RMSProp and looks like this:

mₜ,ⱼ and vₜ,ⱼare estimates of the first and second moments (i.e., mean and variance) of the gradients, hence the name of the algorithm.
A potential problem with Adam is the fact that since mₜ,ⱼ and vₜ,ⱼ are initialized as zero vectors, they tend to be biased towards 0, especially in the initial time steps and when β₁ and β₂ are close to 1 (i.e. we preserve a lot of information from the previous time steps and add relatively less during this one). To combat this, the authors apply a neat trick:

These vectors are then used in the update rule as follows:

Issues with gradient descent
In contrast to its huge speed advantage, the gradient descent methods suffer two major drawbacks:
- The tuning of the learning rate
- Getting stuck in local minima/plateaus
Usually to tackle the first problem people take a small random subset of their data set and perform a line search over a list of values. Ideally in each update step, one can solve another optimization problem with respect to the learning rate parameter, but this would impose a significant computational overhead. Regarding the second problem, local minima and plateaus, which always arise in deep learning problems, as the loss functions are high dimensional and of complex curvatures, the gradient descent methods converge in local minima and plateaus. The reason behind this is pretty simple - the gradient of the loss function at these points is 0. To tackle this issue one has to apply a second-order method that uses both first and second-order derivative information. A very famous example is Newton's method. In fact, it also solves the problem with learning rate choice, which is replaced by the second-order derivative information. Unfortunately, along with these advantages, it is impractical for solving high dimensional problems as it requires the computation of the inverse Hessian matrix, which would be extremely slow.
Sum up
Gradient descent is an optimization algorithm that allows neural networks to learn based on training data. It relies on updating the neural network’s weights in the direction opposite to the loss function’s gradient, which is the vector of its partial derivatives with respect to each weight and bias. This is generally done on mini-batches of the training data to make it computationally cheaper. More modern variants have been proposed, but almost all have their roots in gradient descent.







