
Manual QA is a significant part of the annotation pipeline. Annotation companies report that 40 percent of the annotation time can be spent on manual QA. As a result, finding ways to reduce QA testing time can have a significant impact on annotation costs.
At SuperAnnotate, we’ve developed a tool to accelerate the QA process. This article discusses SuperAnnotate’s features that speed up the quality assurance process substantially. It presents several automation tools within the platform listing specific use cases in which a major acceleration of the QA process can be obtained. We also explored various ML algorithms that can detect over 90 percent of mislabeled instances in data while accelerating the QA process up to 4 times.
Outline
- Problem with noisy annotation in data
- Manual QA acceleration
- QA automation
- Conclusion
Problem with annotation noise in data
The importance of model accuracy and the impact of annotation noise
In real-world applications, the performance of machine learning (ML) systems is of crucial importance. ML models heavily rely on the quality of annotated data, but obtaining high-quality annotations is costly and requires extensive manual labor.
In any annotation pipeline, regardless of the data collection method, i.e., human or machine, several factors inject annotation noise in data. As a result, even the most celebrated datasets contain mislabeled annotations.

Recent studies show that both natural and malicious corruptions of annotations tend to radically degrade the performance of machine learning systems. Deep Neural Networks (DNNs) tend to memorize noisy labels in data, resulting in less generalizable features and poor model performance (Zhang et al.)
Therefore, extensive quality control of annotated data is required to clean annotation noise and improve model performance.

Manual QA acceleration
SuperAnnotate’s QA pipeline
Quality Assurance of annotated data is time-consuming and requires particular attention. Annotation tools need to provide reliable and scalable QA pipelines to accelerate the QA process. SuperAnnotate provides interlinked annotation and QA processes within the same platform. As a result, QA systems do not require additional management.
The design of SuperAnnotate’s QA system guarantees an efficient process and ensures a minimal probability of error.
Pinning images to reduce common errors
Sharing repetitive labeling mistakes across the annotation team is essential to reduce systematic errors throughout single or multiple annotation projects. SuperAnnotate’s pin functionality is designed specifically for this cause.
Once the reviewer notices a recurring error, they can share this information through pinned annotations instead of extensive project instructions. Pinned annotations will appear first in the annotation editor to immediately grab the annotation team’s attention.
This functionality is highly efficient since it allows the project coordinator to instantly share common instructions, eliminating the spread of systematic errors.

Approve/disapprove functionality
Apart from various image-level QA tools, SuperAnnotate also provides instance-level QA functionalities. The latter is designed to help the QA focus on a specific instance area. As a result, no error is overlooked, at the time a meticulous QA is time-efficient.
Additionally, the Approve/Disapprove functionality works on the level of individual instances. If a QA specialist disapproves of an annotation, they can send it back to the Annotator for correction. The QA specialist can send the annotation back to the Annotator as many times as needed until the annotation is corrected. Once approved, the annotations can be exported from the platform.
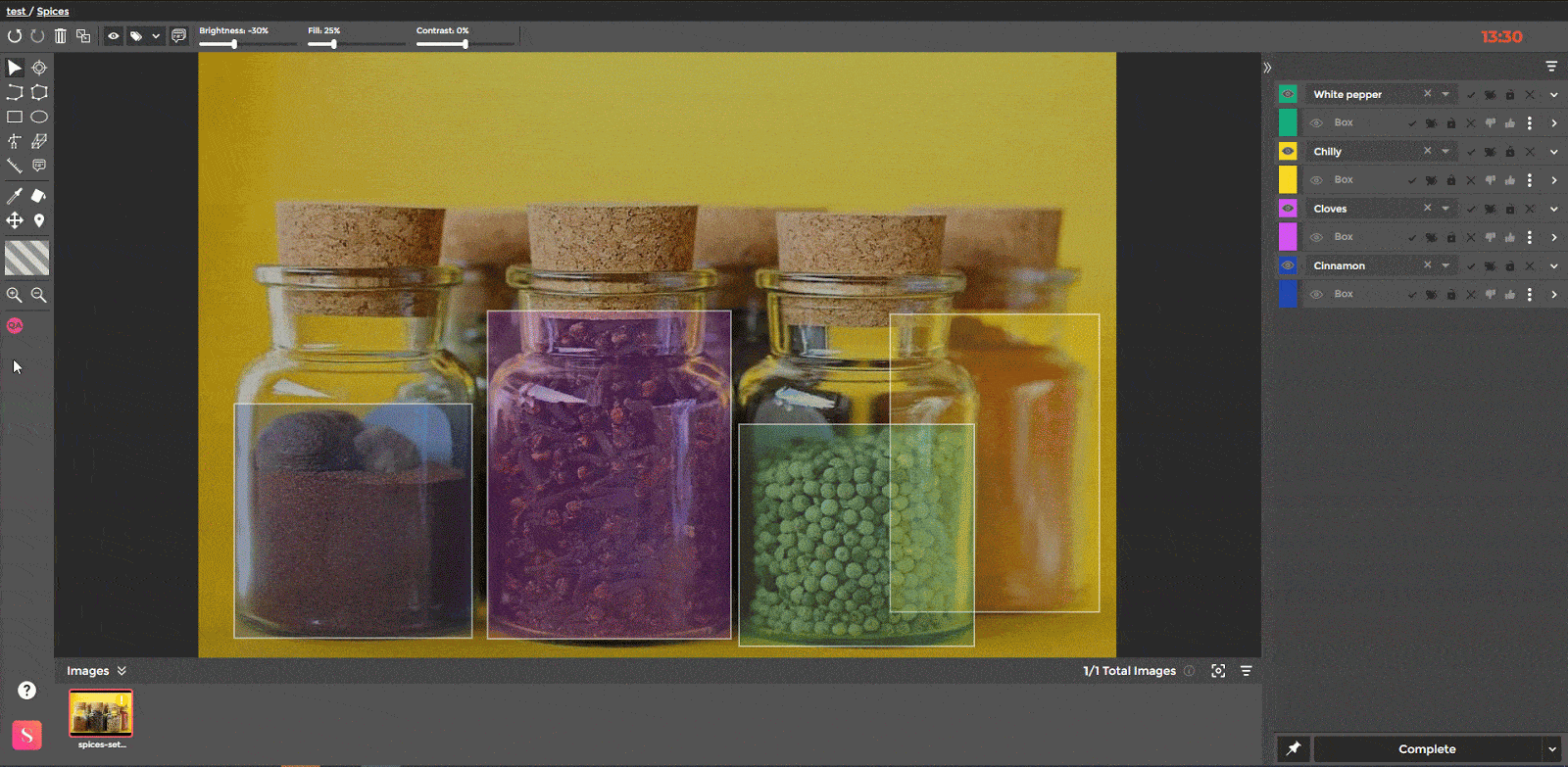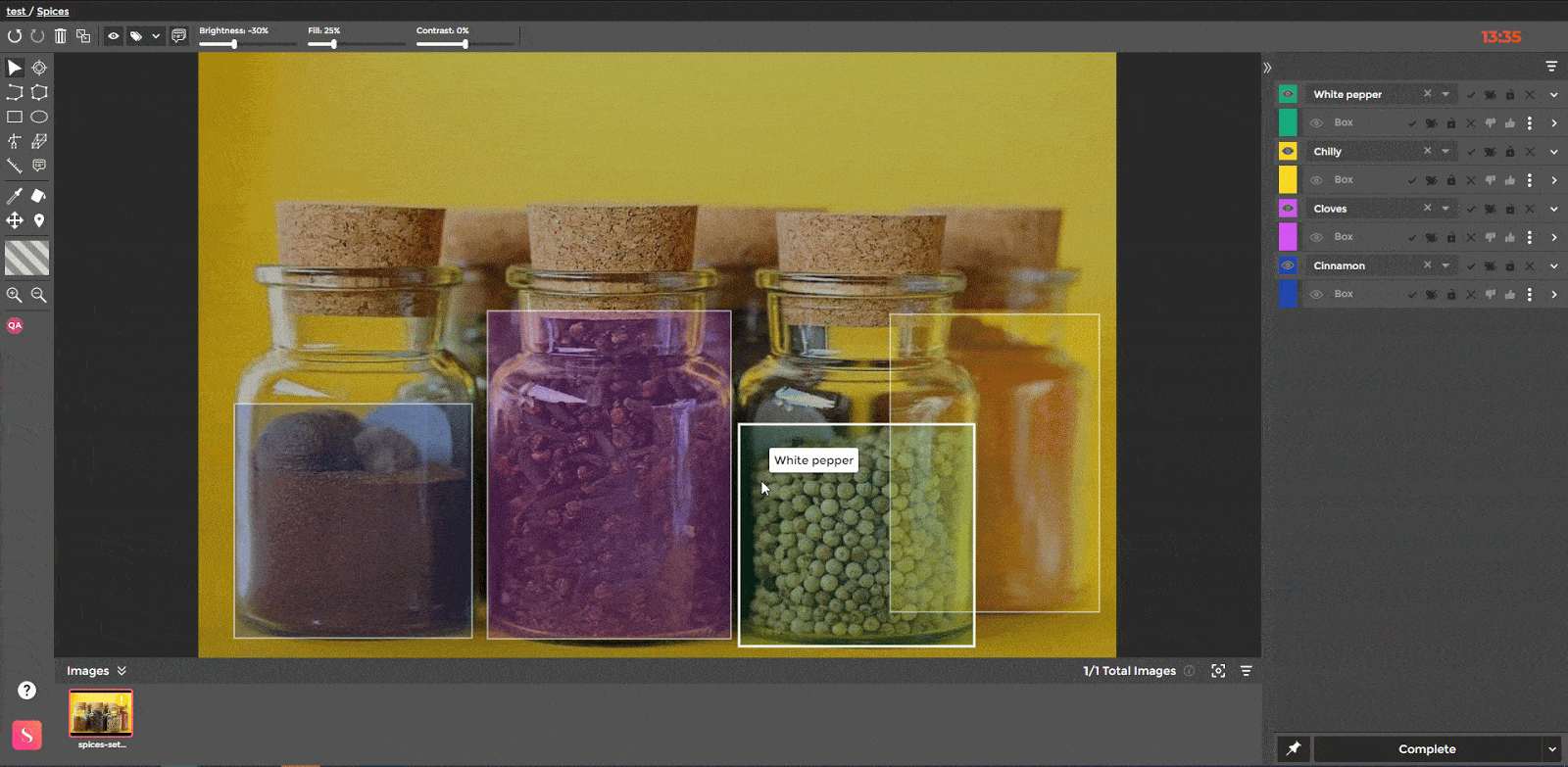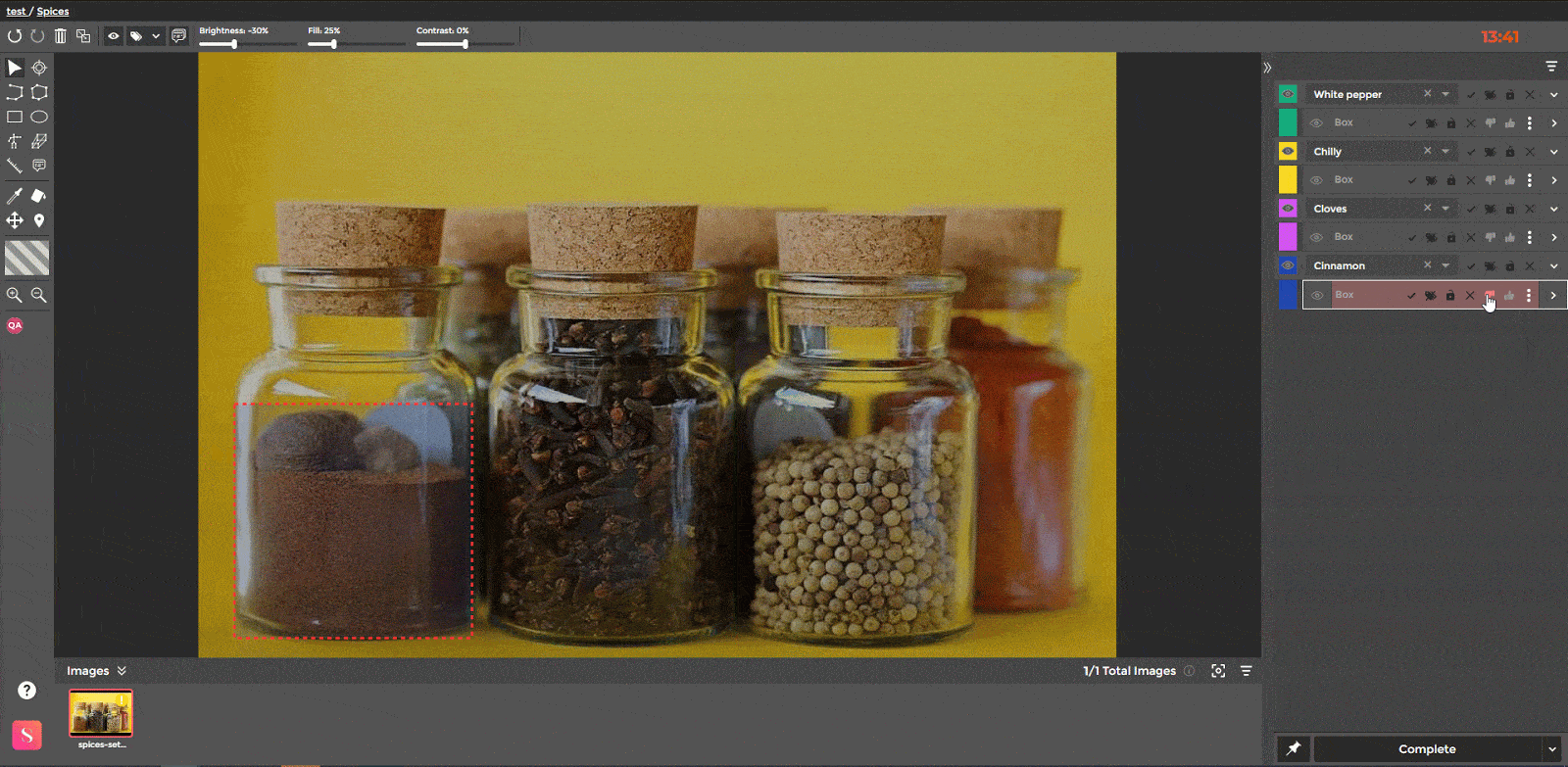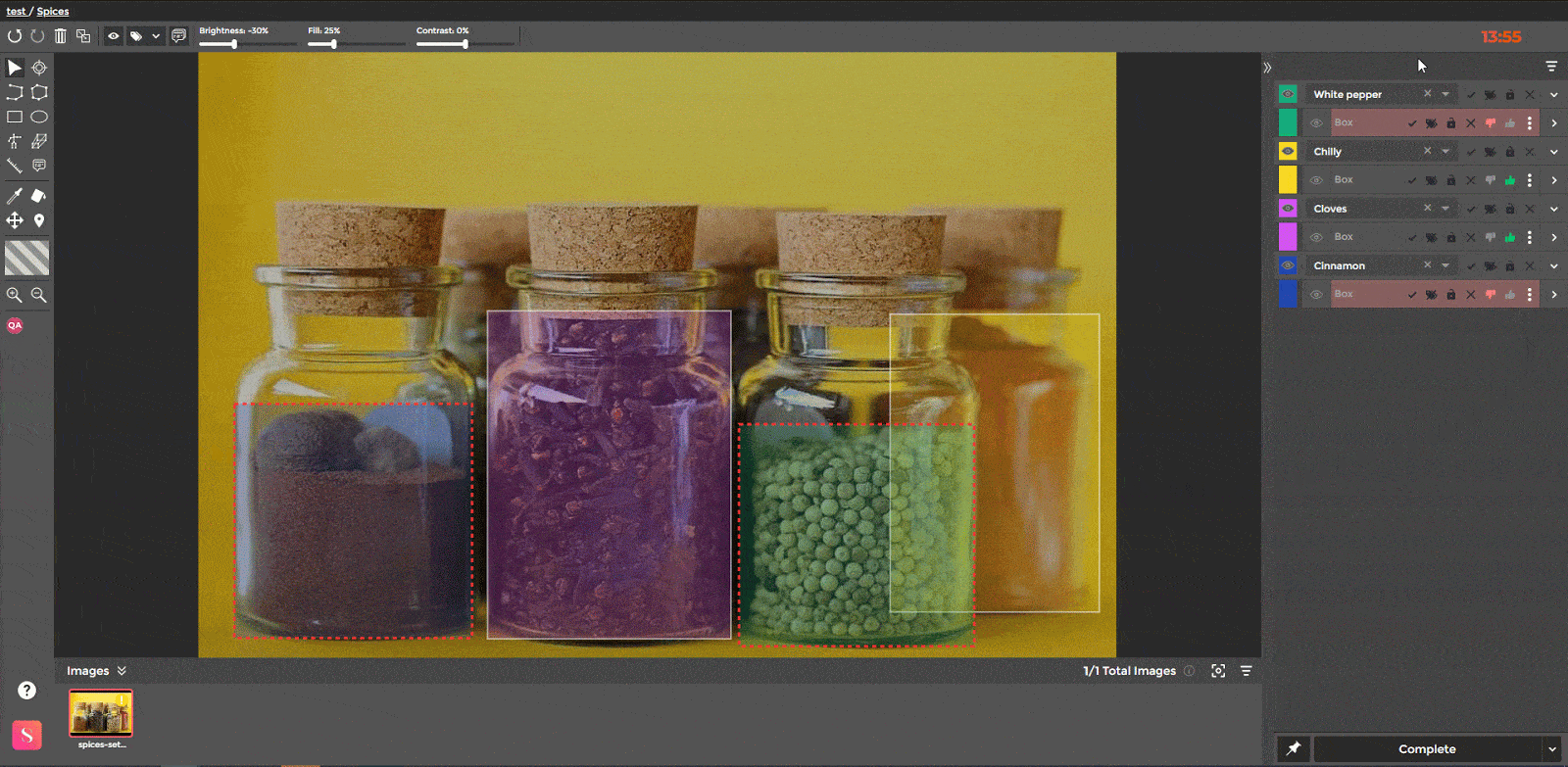
The QA mode is another useful tool for manual instance inspection. When enabled, the annotations are visually isolated from the background. This allows the user to distinguish between instances and the underlying objects, making the instance inspection easier.
All listed features extensively accelerate the manual QA process. However, machine learning techniques that automatically detect annotation noise can provide an additional level of automation.
QA automation
ML for QA automation
QA of annotated data takes around 40 percent of the annotation time.
On average, only a small fraction of annotated data contains noise. Still, QA is applied to the entire dataset, and monitoring clean data costs the annotators extra time and resources. An automation method could substantially cut down the QA process of clean data by isolating a set of risky annotations. So, our goal is to determine ML techniques that identify noisy annotations in data with high precision and recall.
Current research
Learning on datasets that contain annotation noise has been an active research area in ML. Several methods use predictions from DNNs to detect label noise and modify training loss (Reed et al., 2015; Tanaka et al., 2018). These methods do not perform well under high noise ratio as the domination of noisy annotations in data causes overfitting of DNNs. Another approach is to treat small loss samples as clean annotations and allow only clean samples to contribute to the training loss (Jiang et al., 2017). Ultimately, this research area’s core challenge is to design a reliable criterion capable of identifying the annotation noise.
A significant amount of research in this area is focused on classification with noisy labels. The proposed methods range from detecting and correcting noisy samples to using noise-robust loss functions. Unsupervised and semi-supervised learning techniques are also relevant to this task since those require few or no labels. Mislabeled samples that are detected without label correction can be used as unlabeled data in a semi-supervised setting (Li et al. 2020).
Going beyond classification makes things far more challenging. In classification, the existence of an object per image is guaranteed. So, the noisiness criterion can be defined between predicted and annotated image labels. However, in more complex tasks such as object detection, the correspondence between predicted and annotated instances is less trivial. Even though research in this area is in its initial state, several methods suggest valid measures to indicate both localization and label noise in object detection (Pleiss et al 2020, Chadwick et al. 2019).
Proposed method
Consider the task of object detection on a dataset that contains mislabeled annotations. Several techniques use DNN predictions to identify label noise in data. Based on this concept, we propose the following algorithm.
- For each bounding box annotation, we obtain the matching prediction that has the maximum IOU.
- Compute L2 distance between one hot vector of an annotated class and Fast RCNN softmax logits of the matched prediction. This distance serves as a mislabel metric for annotations. We treat this number as the probability of annotation being mislabeled. As we aim to achieve maximal recall and precision in mislabel detection, we select an optimal threshold to attain the desired objective. This defines the split of data between clean and mislabeled annotations by the given criterion.

Along with mislabeled detections, we also suggest considering the most confident predictions as missing annotations.
Experiments and results
To evaluate the performance of our method, we used PASCAL VOC as a toy dataset. When we manually injected asymmetric label noise in 20 percent of box annotations, the described mislabel criterion resulted in the precision-recall curve shown below.

Here, recall determines the portion of annotation noise captured, and precision identifies the fraction of data validated as clean.
Based on the PR curve above, using optimal mislabel threshold results in over 93 percent recall. This proves the reliability of our method, as we capture the dominant fraction of annotation noise. Along with high recall, we obtained over 75 percent precision, which attributes to validating ¾ of annotations as clean. This cuts manual inspection time over the whole dataset by a margin of 4, resulting in extensive automation for the manual QA.
Note that detected risky annotations contain clean samples apart from correctly detected mislabeled instances. Those are the images that were hard to capture by the detection model and thus are misclassified as risky. Distinguishing between these two categories is a challenging problem for further research.
You can find the source code for the discussed experiments at our GitHub repository.
Also, consider our Colab tutorial as a step-by-step guide to reproduce the given results.
Automate Approve/disapprove functionality
Once mislabeled annotations are captured by ML techniques, SuperAnnotate allows users to import the detected information to the platform through the error key of SA formatted annotations. Just set the error key in mislabeled annotations and import SA formatted JSONs to SuperAnnotate via Python SDK.


Discussed pipeline provides complete automation of Approve/Disapprove functional.

Conclusion
QA automation is of crucial importance as it constitutes a significant portion of annotation time. This article shows that using proper algorithms and associated tools can help us detect mislabeled annotations with high precision while spending 4x less time on QA.






