
In the ever-expanding realm of artificial intelligence (AI), object detection stands out as a foundational pillar with transformative implications. At its core, object detection goes beyond mere image classification—it identifies and locates multiple objects within an image, assigning them precise bounding boxes and categories. This capability has propelled advances in numerous applications, from self-driving cars to smart surveillance systems. As we delve deeper into its nuances and potential, it is crucial to understand the definition and relevance of object detection within the broader scope of AI.

The evolution of object detection has been a captivating journey, reflecting the broader shifts in the world of AI. In its early stages, object detection relied heavily on hand-engineered features—meticulously crafted algorithms that were designed to pick up specific attributes of objects. While innovative for their time, these detectors were often constrained by their rigidity and lack of adaptability to diverse scenarios. However, with the advent of deep learning, the landscape dramatically changed. Neural networks, especially convolutional neural networks (CNNs), introduced a paradigm shift, to learn and extract features from raw data automatically. As we traverse this narrative, we will explore the transformation from the humble beginnings of hand-tuned feature extraction methods to the groundbreaking deep learning techniques that dominate the field today.

Understanding the Basics of Object Detection
Before diving into object detection applications, use cases, and basic object detection methods, it is crucial to establish a clear-cut understanding of object detection itself. The term is often used interchangeably with techniques such as image classification, object recognition, image segmentation, and more. However, it must be acknowledged that many of those mentioned above are separate tasks that commonly fall under object detection. It is inaccurate to use them synonymously with one another since each pertains to an equally vital and distinct task.

What is object detection?
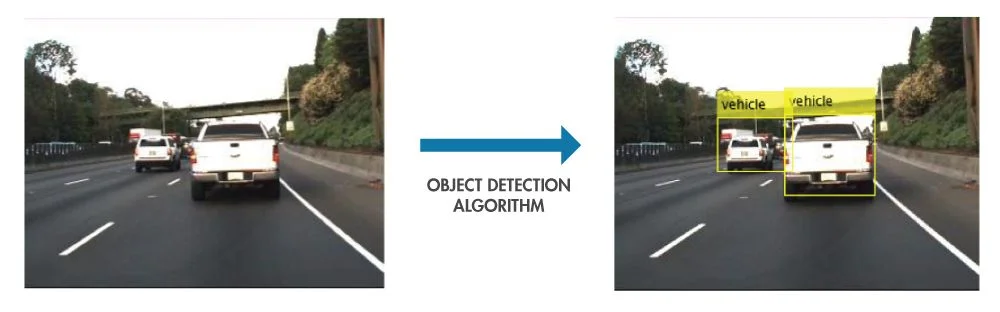
Object detection is a profound computer vision technique that identifies and labels objects within images, videos, and even live footage. Models that perform object detection are trained with a surplus of annotated visuals in order to carry out this process with new data. It becomes as simple as feeding input visuals and receiving a fully marked-up output visual. We will discuss object detection models in more depth a little later. A key component is the object detection bounding box, which identifies the edges of the object tagged with a clear-cut quadrilateral — typically a square or rectangle. They are accompanied by a label of the object, whether it be a person, a car, or a dog to describe the target object. Bounding boxes can overlap to showcase multiple objects in a given shot as long as the model has prior knowledge of the items it is tagging.
Object detection vs. other tasks
Let us break down the other three computer vision tasks individually for a greater understanding of each one:
- Image classification: This is the prediction of the class of an item in an image. For example, when you carry out a reverse image search on Google, you are likely to receive a note that says “might include ‘x’, with the ‘x' being anything that the technology detects as the primary object of the image. Image classification can show that a particular object exists in the image, but it involves one primary object and does not provide the object’s location within the visual.
- Segmentation: Otherwise known as semantic segmentation, it is the task of grouping pixels with comparable properties together instead of bounding boxes to identify objects.

- Object localization: The difference with object detection is very subtle yet evident. Object localization seeks to identify the location of one or more objects in an image, whereas object detection identifies all objects and their borders without much focus on placement.

Core challenges in object detection
Despite its advancements, object detection is filled with challenges that researchers and engineers grapple with to fine-tune models and improve accuracy. These challenges ensure that the field remains vibrant with continual innovation. As a general disadvantage of object detection, one can easily point to the lack of precision. When automating safety-critical tasks, such as autonomous driving, medical autonomous machines, or analyzers, engineers always prefer to use instance segmentation instead of object detection, as instance masks are more precise than a bounding box placed around the instance. In addition, there are more specific and low-level challenges that the models face:
- Variability in object appearance: Objects can appear in various sizes, shapes, and orientations within images. The same object or subject might look different under different lighting conditions, from different viewpoints, or in varied backgrounds. The ability of a model to recognize such diverse representations of an object is crucial.

- Scale variations: Objects in images can range from tiny to very large. Detecting both small objects (like a distant bird) and large ones (like a close-up face) in the same image requires models to be scale-invariant or operate at multiple scales.

- Occlusions: Objects of interest are often partially or largely obscured by other objects. For instance, a person standing behind a tree or a car partly hidden behind a building. Handling occlusions is pivotal for accurate object detection.
- Background clutter: Objects might be set against backgrounds with confusing patterns or multiple overlapping objects, making it challenging to distinguish the foreground (object of interest) from the background.

- Intra-class variability: Objects within the same class can vary significantly in appearance. For example, the "dog" class includes diverse breeds with varied shapes and sizes. Models should generalize well across such intra-class variations.

Usually, addressing these challenges requires a blend of innovative modeling, efficient training strategies, and quality training data. As the field progresses, the quest to tackle these issues drives both the development of novel techniques and the refinement of existing ones.
Early traditional approaches in object detection

Before the deep learning revolution took hold, object detection largely depended on manual feature extraction. These methods focused on crafting specific descriptors from images that were then used for detection tasks. Here is a brief overview of early methods of hand-engineered features that were used in object detection:
- Harris corner detector: Proposed in the 1980s, this method focused on detecting corners as interest points in an image. The idea was that corners provide a unique feature that can be reliably detected due to their distinctiveness compared to edges or flat regions.
- Scale-invariant feature transform (SIFT): Developed by David Lowe in 1999, SIFT extracts and describes local image features that are invariant to scale, rotation, and affine transformations, as well as being robust to changes in illumination. SIFT features were often used to match objects or scenes between different images.
- Speeded up robust features (SURF): An evolution of SIFT, SURF was designed to be faster and more efficient while retaining robustness against transformations. It was introduced in 2006 and relied on integral images to expedite feature extraction.
- Histogram of oriented gradients (HOG): Introduced by Navneet Dalal and Bill Triggs in 2005, HOG descriptors focus on capturing an object’s structure or shape by examining the orientation of gradients in local regions of an image. HOG became particularly popular for pedestrian detection in images.
- Viola-Jones object detection framework: Developed in 2001 by Paul Viola and Michael Jones, this was one of the first effective real-time object detection methods. The framework utilized Haar-like features to detect objects, especially faces, in images. A cascade of classifiers was used, allowing for efficient real-time performance by quickly discarding negative samples.
- Deformable part models (DPM): DPM, introduced by Felzenszwalb et al., was based on mixtures of multi-scale deformable part models. It represented objects by parts arranged in a deformable configuration and used HOG features. DPM was notably robust against object deformation and variability in pose.
These early methods laid the groundwork for understanding and detecting objects in images. However, the need to hand-design features was labor-intensive, domain-specific, and often lacked the generality and robustness offered by later deep learning-based methods.
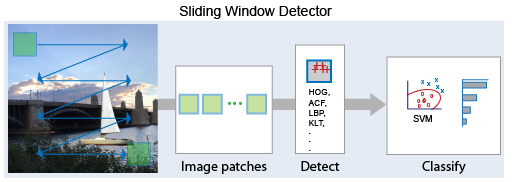
Sliding window approach
The sliding window approach is a technique traditionally used in object detection tasks before the invention of more advanced deep learning methods. The central idea is straightforward: a window (a bounding box) of a predefined size "slides" or moves across the image, covering all possible positions and scales. The sliding is done from left to right and top to bottom. Then, for each extracted bounding box hand, engineered features like HOG or SIFT are computed, which is then fed into a trained classifier, usually an SVM.

Objects of different sizes, or even the same objects of different scales, were this approach's main problem. This exact same operation was performed on several resized versions of the same image to detect objects of different scales, and the results were aggregated. This caused great computational expenses, and the lack of powerful GPU computing then made it impractical for real-time object detection. Another problem was that this strategy used fixed-size bounding boxes, which means it could not fit well with objects with a different aspect ratio than the window.
Deep learning vs. machine learning
Now that you have a grasp of our basic introduction to object detection, it is time to look at the two main models of object detection: deep learning and machine learning. Data analysts commonly rate deep learning approaches as relatively state-of-the-art approach since it is considered to be much more intuitive and do not require as much human interference. Ultimately, both approaches yield accurate results, but we will concentrate on object detection with deep learning this time.

What is object detection with deep learning?
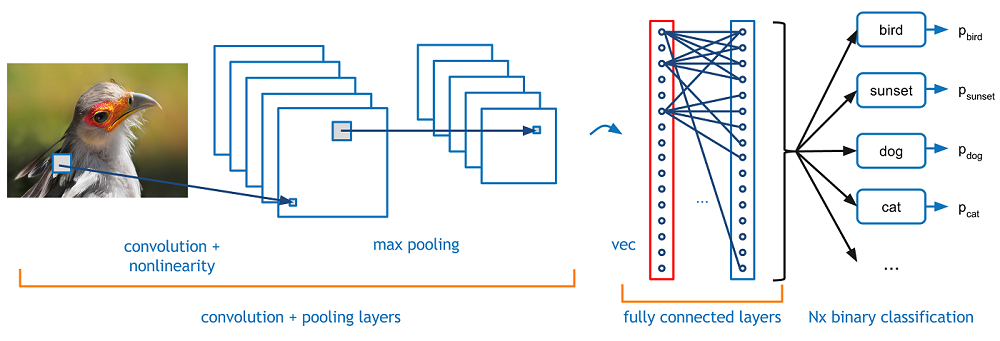
What sets object detection with deep learning apart from alternative approaches is the employment of convolutional neural networks (CNN). The neural networks mimic that of the complex neural architecture of the human mind. They primarily consist of an input layer, hidden inner layers, and an output layer. The learning for these neural networks can be supervised, semi-supervised, and unsupervised, referring to how much of the is annotated, if at all (unsupervised). Deep neural networks for object detection yield by far the quickest and most accurate results for single and multiple object detection since CNNs are capable of automated learning with less manual engineering involved. There is a world to unpack regarding deep learning and CNNs, but today, we will only focus on critical points that regard object detection algorithms and models.
Methods and algorithms
Object detection is not possible without models designed especially for handling that task. These object detection models are trained with hundreds of thousands of visual content to optimize the detection accuracy on an automatic basis later on. Training and refining models are made efficient through the help of readily available datasets like COCO (Common Objects in Context) to help give you a headstart in scaling your annotation pipeline.
Early deep learning-based object detection models were categorized into two classes: one-stage and two-stage detectors. One-stage object detectors direct prediction, eliminating completely the region proposal step. On the other hand, two-stage object detectors are composed of region proposals followed by classification and refinement of the proposal.

Two Stage Object Detectors: The RCNN Family
The RCNN family of object detectors is very popular and has been the state-of-the-art object detection model for a long time. The evolution of the models in this family is very interesting and houses many insights that can be applied in any field of utilizing deep learning models. Let us get to an overview of the key developments in their architectures.
RCNN
The region-based convolutional neural network (RCNN) was proposed by Ross Girshick et al. in 2014 and was one of the first successful deep learning approaches to detect objects. RCNN operates by generating a set of region proposals using an external algorithm, applying a pre-trained convolutional neural network (CNN) to each proposal to extract features, and finally classifying each proposal using a support vector machine (SVM).

Fast-RCNN
The fast region-based convolutional neural network (Fast R-CNN) was proposed by Ross Girshick in 2015 and was designed to improve the speed and accuracy of object detection. Fast R-CNN operates by using a single shared CNN to extract features from the entire image. Then, it uses the region of interest (RoI) pooling to extract fixed-length feature vectors for each region proposal. These feature vectors are then fed into a fully connected layer set that performs object classification and bounding box regression.

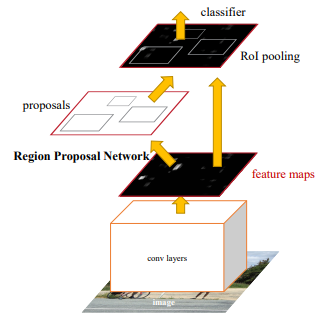
Faster-RCNN
The faster region-based convolutional neural network (Faster R-CNN) was proposed by Shaoqing Ren et al. in 2015, representing a major breakthrough in deep learning object detection. Faster R-CNN operates by using a region proposal network (RPN) first to generate region proposals directly from the convolutional neural network features rather than using an external algorithm. The RPN shares convolutional layers with the object detection network, which allows it to be trained end-to-end with the rest of the network. Faster R-CNN also introduced a new loss function that jointly optimizes object classification and bounding box regression, which helps to improve accuracy.

The evolution of object detection models alongside other prominent convolutional neural networks are presented in depth in our article, which we recommend as a further reading material.
One-stage object detectors
One-stage object detection methods aim to simplify the object detection pipeline by predicting object class labels, and bounding box coordinates in a single pass, thereby often achieving faster processing speeds than two-stage methods. Given their efficiency, they are popular choices for real-time object detection. Some of the prominent one-stage object detection models are YOLO, SSD, and RetinaNet, which we will introduce separately.
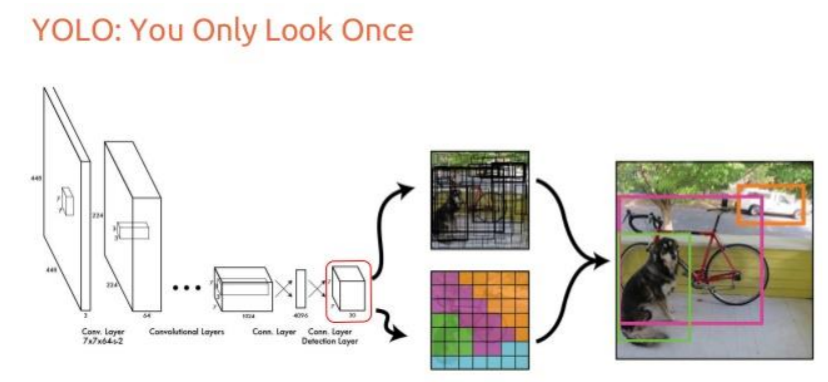
YOLO: You Only Look Once
YOLO divides an image into a grid and predicts bounding boxes and class probabilities for each grid cell. Unlike sliding window and region proposal-based techniques, YOLO looks at the whole image only once, hence the name. The original YOLO has seen multiple versions, with YOLOv2 (YOLO9000), YOLOv3, and YOLOv4 introducing various improvements in accuracy, speed, and the ability to detect a wider range of object sizes. Its tiny versions are extremely fast, making it suitable for real-time object detection and even deployment on edge devices. Usually, it has a good balance between precision and recall.

SSD: Single shot multibox detector
SSD predicts multiple bounding boxes and class scores for those boxes in one pass. It does this by using multiple feature maps from different network layers to predict detections at various scales. It uses a base network (often a VGG16 trained on ImageNet) for feature extraction. This network is truncated before the fully connected layers, allowing the model to take inputs of any size. One of SSD's key contributions is using feature maps from different layers in the network to predict detections at multiple scales. This makes it capable of detecting objects of varying sizes, addressing one of the significant challenges in object detection. Smaller feature maps are used to detect larger objects, and larger feature maps detect smaller objects.

RetinaNet
While RetinaNet is technically a one-stage detector, it introduced a novel loss function called the "Focal Loss" to address the class imbalance issue, which was a challenge in one-stage detectors. This allowed RetinaNet to achieve accuracy comparable to two-stage methods while retaining the speed of one-stage detectors.

To conclude, one-stage detectors have carved a niche in scenarios where speed is of paramount importance, such as real-time surveillance, autonomous driving, and interactive applications. Over the years, the performance gap between one-stage and two-stage detectors has narrowed due to innovations in model architectures and training techniques, making one-stage methods increasingly compelling for a wide range of applications.
The rise of transformer-based models in object detection
Transformers, deep learning models initially proposed for sequence-to-sequence tasks in natural language processing, have recently made groundbreaking advancements in the field of computer vision, notably object detection. By leveraging the self-attention mechanism, which allows models to weigh the significance of different parts of input data, transformers can capture long-range dependencies and intricate patterns in visual data, which traditional convolutional networks might miss.
While convolutional neural networks (CNNs) have been the mainstay for image processing tasks, they inherently rely on the locality of pixel data. CNNs work on local receptive fields and capture hierarchical patterns by stacking multiple layers. On the other hand, transformers use self-attention mechanisms to weigh the importance of different parts of an image, allowing them to establish global relationships between pixels.
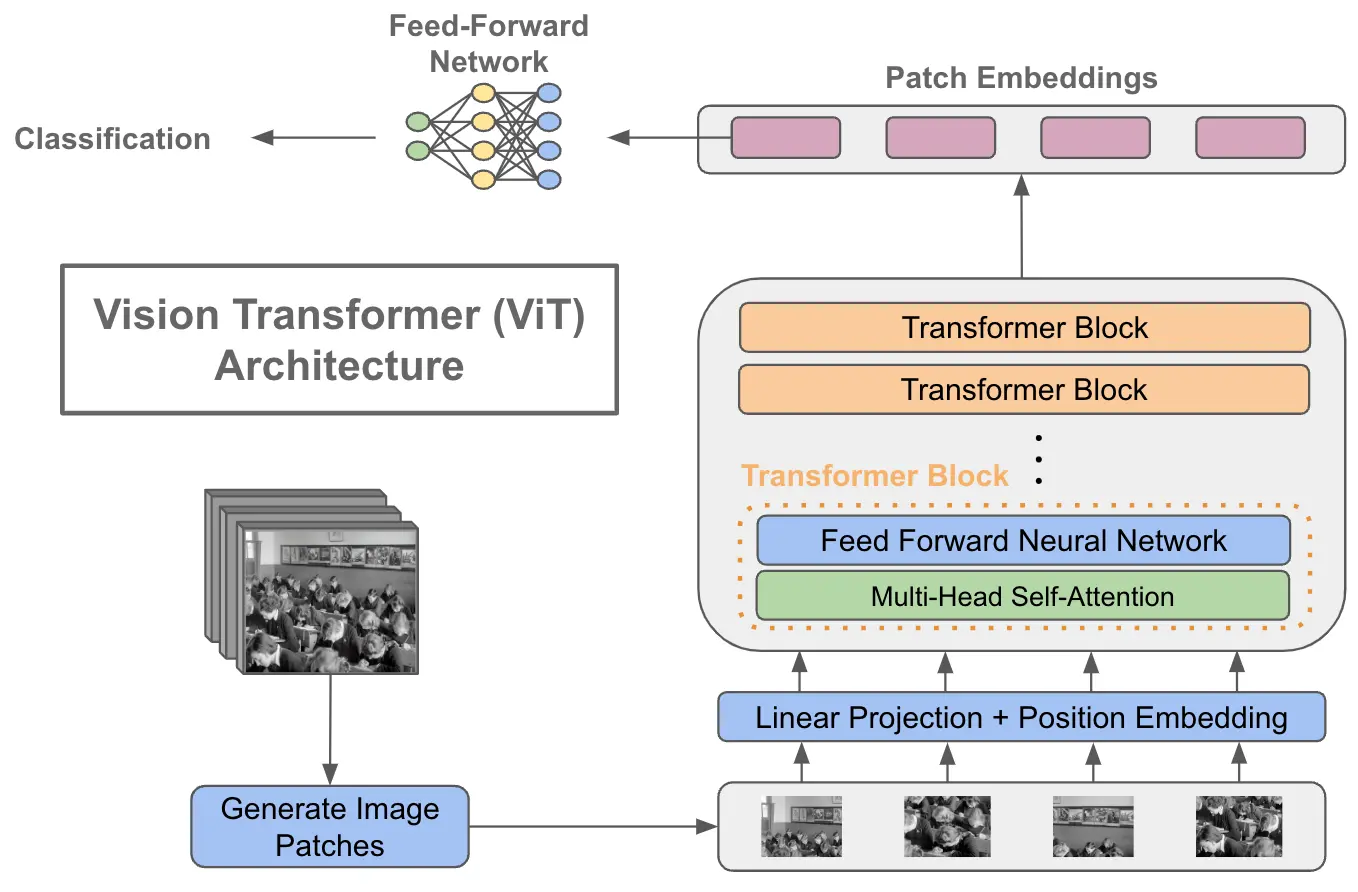
One of the earliest and most influential transformer models for vision tasks is the vision transformer (ViT). Instead of using CNNs for feature extraction, ViTs divide an image into fixed-size patches, linearly embed them, and then process the sequence of embedded patches with transformers. To be more precise:
- Tokenization: Images are split into fixed-size patches (e.g., 16x16 pixels). These patches are then flattened and linearly embedded to produce a sequence of tokens.
- Positional encodings: Since transformers do not have a built-in sense of order or position, positional encodings are added to the embedded patches to give the model information about the original position of each patch in the image.
- Processing: The sequence of embedded patches is then processed by a series of transformer blocks, which use self-attention to weigh the importance of different patches relative to each other.
DETR: Detection transformer
DETR is a pioneering model that employs transformers for end-to-end object detection. DETR treats object detection as a direct set prediction problem, eliminating the need for many handcrafted components like anchor boxes. The key distinctions of DETR are:
- Bipartite matching loss: The loss function ensures that each ground truth object is matched to a predicted bounding box. The Hungarian algorithm is employed to find the optimal one-to-one matching between predictions and ground truth. The total loss is a combination of the classification loss for matched predictions and the L1 loss for bounding box coordinates.
- End-to-end training: Traditional object detection models, like Faster R-CNN, utilize anchor boxes as references for predicting bounding boxes. These anchors typically come in different scales and aspect ratios. DETR eliminates the need for such handcrafted components. Instead, it directly predicts bounding boxes in an end-to-end manner without relying on anchor priors.
The Swin transformer further improves DETR by introducing a hierarchical structure with shifted windows, allowing for both local and global self-attention mechanisms. It has proven to be particularly effective, surpassing many state-of-the-art deep learning object detection models of the time in various benchmarks.
Advantages and limitations of transformers
One of the significant advantages of transformer-based models is their scalability. They can be easily scaled up by increasing the number of parameters, often leading to improved performance.
Transformers have shown a remarkable ability to generalize well to different tasks when provided with sufficient data and computing power.
The transformer architecture has proven to be versatile, leading to innovations like hybrid models that combine CNNs and transformers for various tasks.
As a limitation, transformer models for vision are criticized for being computationally heavy and data-hungry, requiring large datasets and powerful hardware for training.
SOTA object detection models
The current state-of-the-art deep learning model to detect objects is Co-DETR, which utilizes the same architecture that was described in the DETR paper in 2020. On the contrary, they made significant changes in the training process and scheduling, which proves that the architecture is pretty powerful and more and more performance improvements can be squeezed out of it.
Evaluating Object Detection Models
It is always important to talk about the evaluation metrics that must be used to understand the model's performance on a holdout set until rolling it out to production. In the case of object detection, two main metrics are usually used to evaluate the models:
- Intersection over union (IoU): IoU is a measure of the overlap between two bounding boxes. It is defined as the area of intersection divided by the area of union of the predicted bounding box (from the model) and the ground truth bounding box (from the dataset). You can read further about this metric in our article about IoU.
- Average precision (AP): For each class, an AP score is calculated primarily by plotting the precision-recall curve and then computing the area under this curve. Then, the mean of AP scores (mAP) across all classes. A higher mAP value indicates a better overall performance of the object detection model across all object classes. We have another informative article about this metric, which you can access here.

Use cases and applications
Object detection with deep learning is very much prevalent in our daily lives, as we have seen with a handful of examples. The extent of its significance in our modern world is far greater than many may initially assume.
Surveillance, security, and traffic
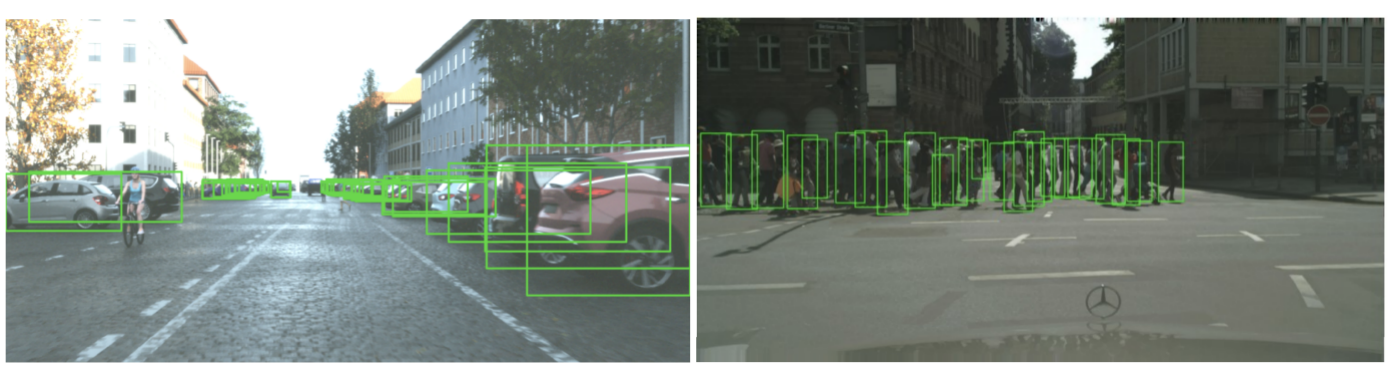
Data labeling aside, object detection in video and real-time footage is the cornerstone of state-of-the-art surveillance. Computer vision aims to constantly exceed expectations and innovate theft detection, traffic violations, suspicious human activity, and so on. All of these processes are gradually being monitored more efficiently than ever before.
Automobile
For autonomous driving, object detection is mandatory for the automobile to determine whether to accelerate, brake, or turn within the next moment. That necessitates object detection that recognizes a collection of things such as cars, pedestrians, traffic signals, road signs, bicycles, motorbikes, and so on.
Medical
Object detection is showing immaculate development in the field of medicine, especially in radiology. Although the technology will not entirely replace the need for expertise for radiologists and other specialists, it will considerably cut down on time spent analyzing hundreds to thousands of ultrasound scans, even x-rays, MRI-s, and CT scans each day.
Retail
Smart inventory management without the need for manual inventory checks, cashier-less shopping experiences, and more are in store for retailers who implement object detection computer vision in their stores.
The Future of Object Detection
The rise of LLMs triggered vast explorations in other directions of deep learning, which resulted in the creation of foundation multimodal models such as CLIP that connect text and image data with joint embedding space, opening limitless possibilities to utilize the power of LLMs for visual data.
In the vision domain, SAM made a significant contribution that allows it to segment any object in any kind of image easily. CM3leon is another advancement in text-to-image and image-to-text domains, which has yet to be released but already shows promising results in image generation and editing tasks.
As you can guess, we are not far from the day a detect anything model is released, making it almost needless for anyone to train a custom object detection model. It is not entirely unnecessary yet, as these foundation models are huge and unsuitable for real-time object detection, which must still be done with traditional deep learning object detection models.
To Recap
Object detection is where image classification and object localization meet to interpret and label a variety of visuals, from images to real-time footage. Object detection models with deep learning algorithms have significantly cut down in process time and speed over the course of only the past decade, which would not be feasible without CNNs. We can clearly see that applications of object detection are prevalent, from the security features on our smartphones to the basis that next-generation smart automobiles rely on. After all, object detection models evolve, grow, and innovate every single day to become more accurate and solve more real-time problems in the modern world.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}