
Having large datasets with high-quality annotations is quintessential in any computer vision task involving deep neural networks. Unfortunately, the process of annotating thousands of images is a time and human-resource-consuming endeavor. Hence, for many companies and university researchers, the annotation time and scalability become a major pain point to scale their research project or business. In this article, we will discuss how to scale and automate your annotation process using transfer learning techniques. Most importantly, we will provide a simple tutorial of how transfer learning works and how it can be done without using a single line of code.
- Transfer learning and how it can be applied to the annotation process
- Training new neural networks using SuperAnnotate
- Testing newly trained network
- Wrapping up
Transfer learning (TL) and how it can be applied to the annotation process

In the most general terms, transfer learning (TL) is an approach in machine learning that focuses on storing “knowledge” that a model has learned in order to solve a given problem A and use that knowledge to help with another related problem B.
Humans have a natural ability to apply knowledge gained from one task to solve an entirely different one. A musician who has learned how to play the piano has already learned music theory, knows how to read sheet music, and can use that knowledge to learn the violin. In other words, if you want to learn the violin, you don’t have to re-learn music theory. Transfer learning tries to solve a similar problem in deep learning. An example that is more related to computer vision is that a neural network that has learned to classify cats and dogs in images has perhaps learned useful features that are specific to canines and felines, which would also help another network classify wolves and tigers.
Now that we know what transfer learning is, how does it help during the image annotation process? What we aim at is improving the speed at which image annotations can be done. Let’s look at the typical process of annotating a particular image with bounding boxes and assigning classes to them.
The hypothesis is that if we have a neural network (NN) that can somewhat accurately make predictions on an input image, then fine-tuning its predictions and annotating the parts of the image that the NN failed to classify will be much faster than annotating the whole image.

In the example above, I deliberately annotated inaccurately to show that sometimes the annotator will need to readjust and resize bounding boxes. What if we had a neural network that could effectively find objects in this image? If we use that network to predict the bounding boxes, it will remain for us to adjust them if need be and focus on instances where the network has failed. We can use SuperAnnotate’s platform and pick any available neural network to do this.
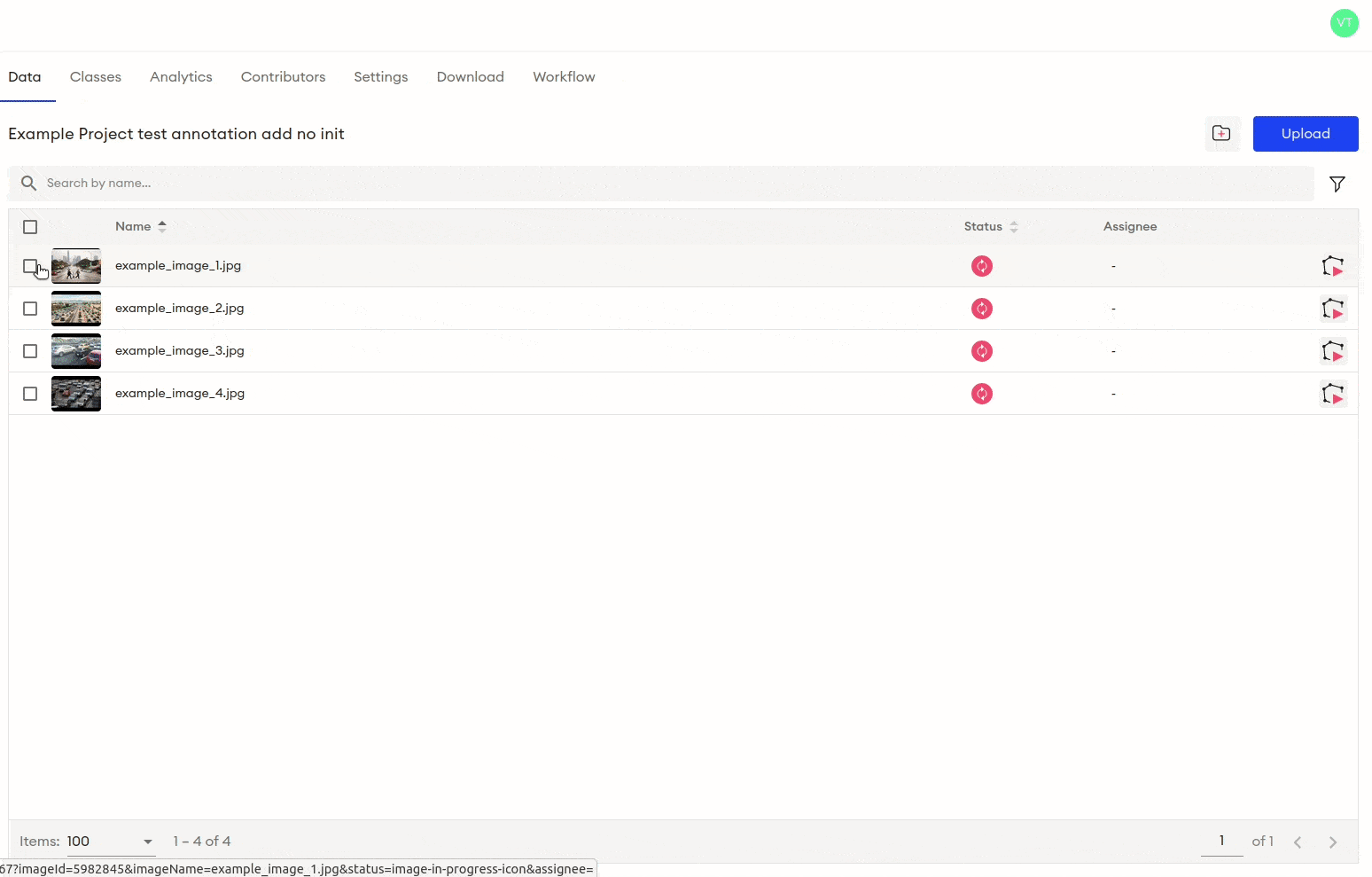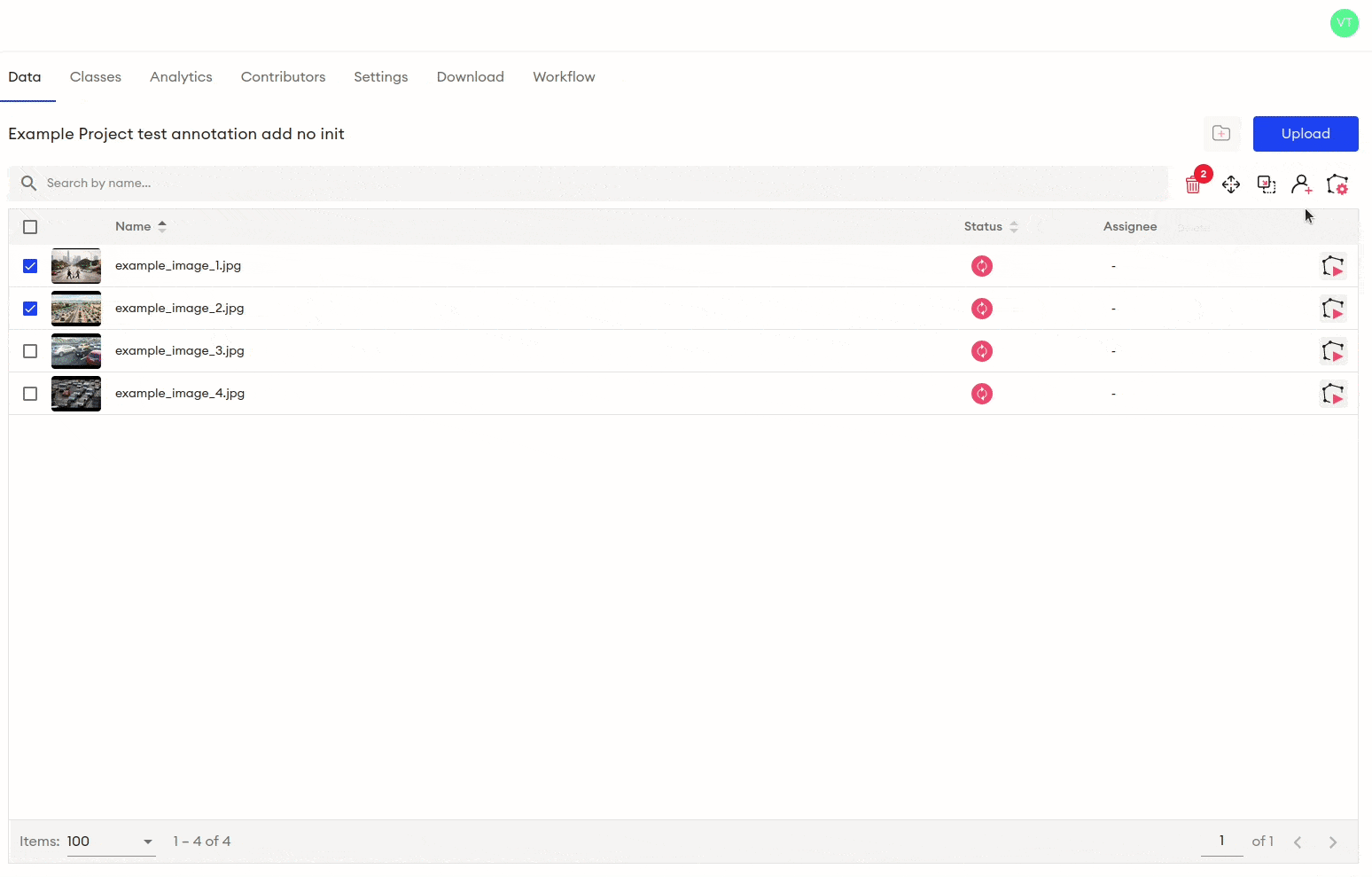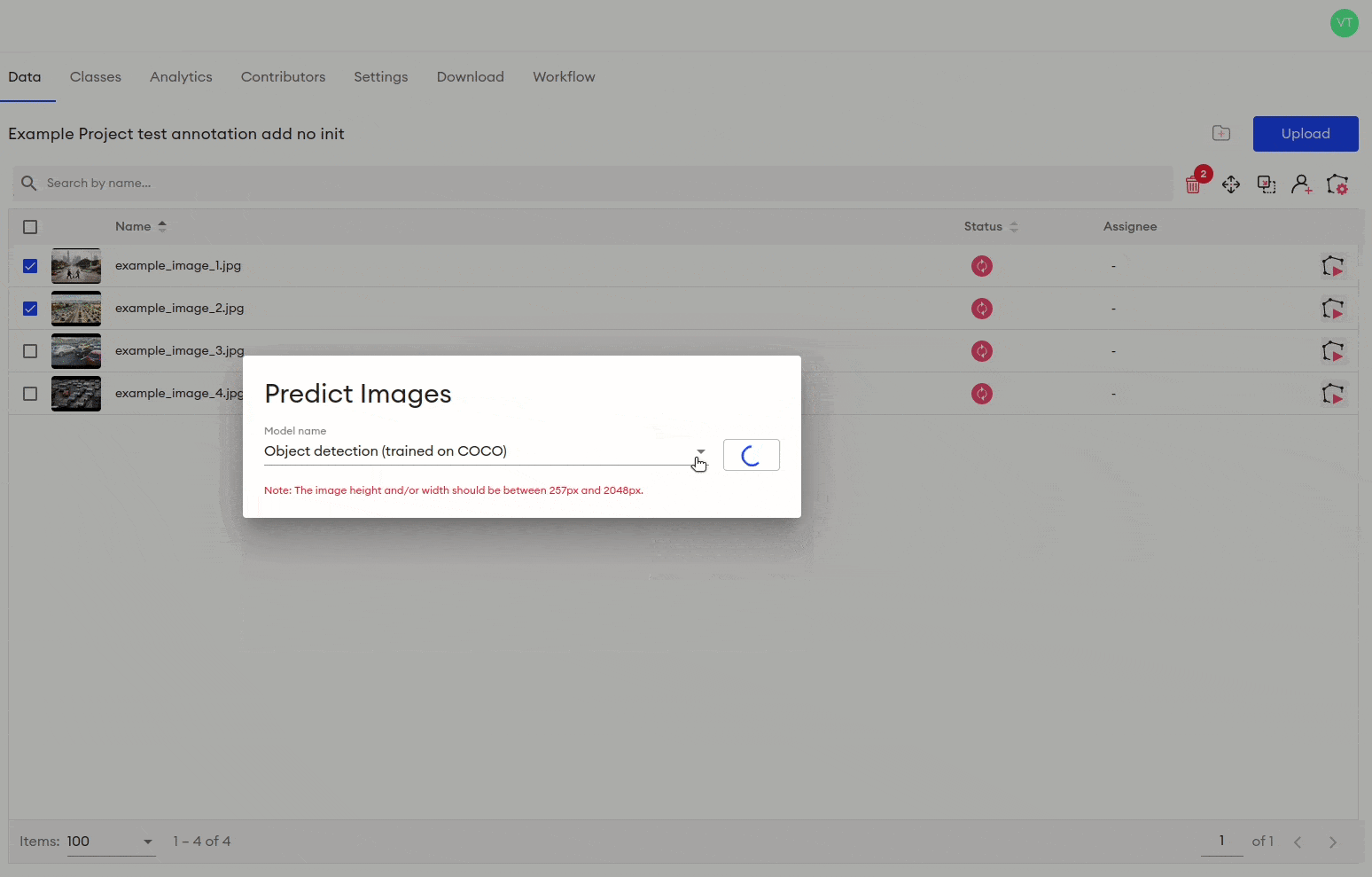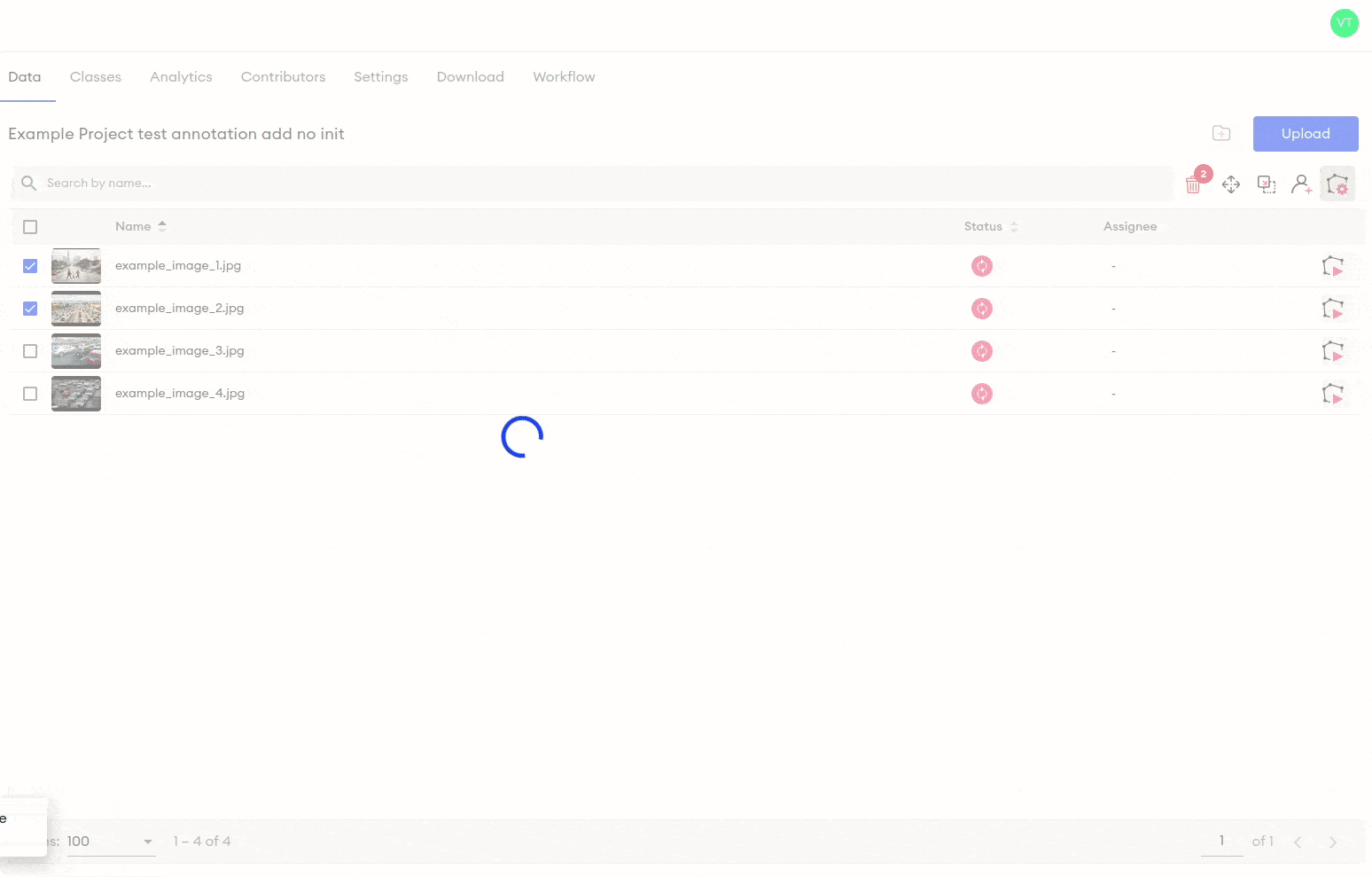
After running the given prediction model, the annotated image looks like this:
The speed improvement will be even more noticeable when we annotate the whole semantic mask instead of bounding boxes only.
By leveraging the power of transfer learning, data augmentation, and pre-trained networks, we can train new models that solve the task we’re interested in with a relatively small number of high-quality annotated images. Using these newly fine-tuned models to partially annotate images, we can tremendously speed up the whole process.
Training new NN using SuperAnnotate
At SuperAnnotate there is a possibility to leverage the knowledge learned by state-of-the-art pre-trained networks in order to create new networks (or to improve the current network) that will suit your annotation needs.
If you are registered in the platform, the workflow for transferring the knowledge from one NN to another will be the following:
1) Click on the Neural Networks tab.
2) Click the New Model.
3) Fill in the model name and description.
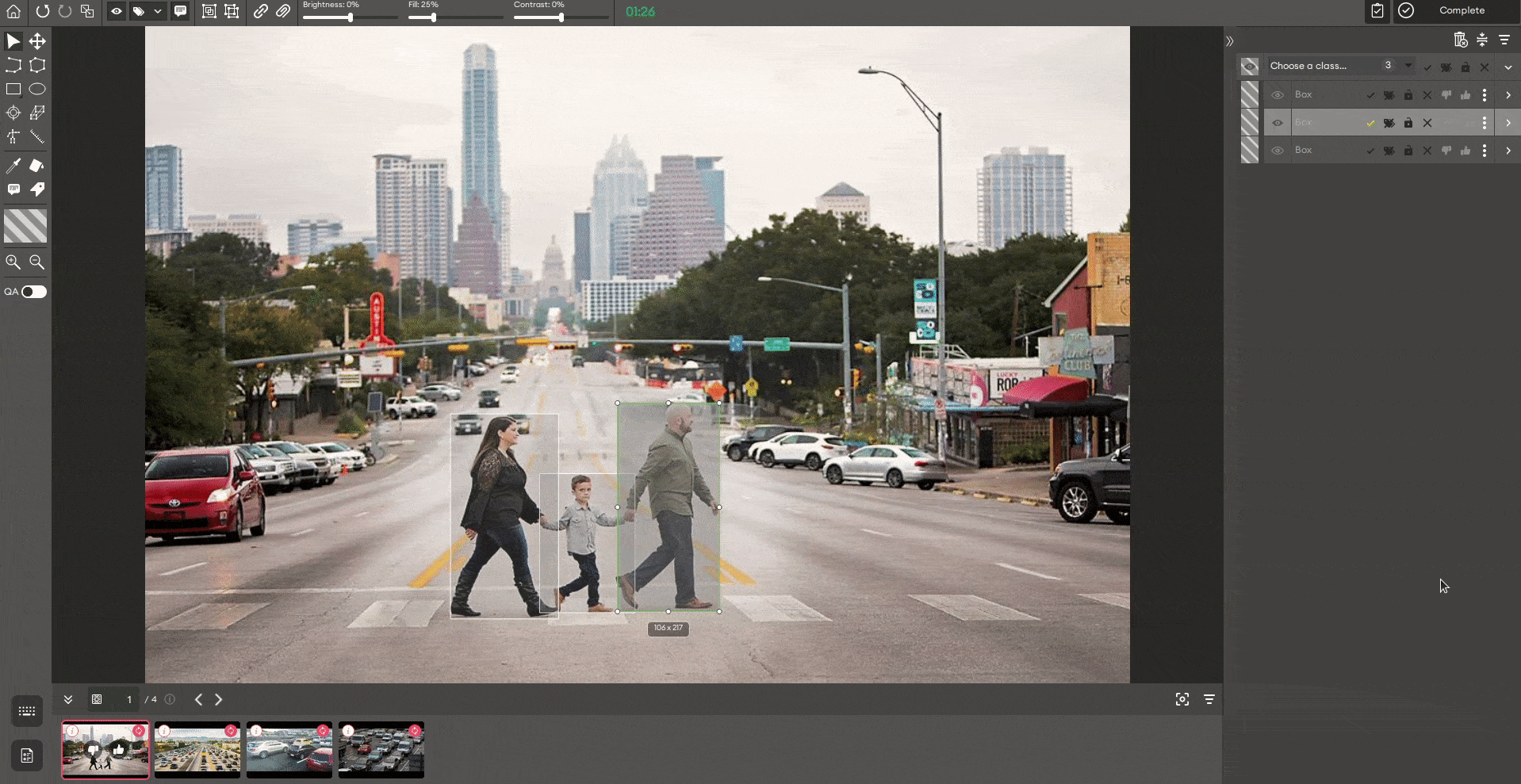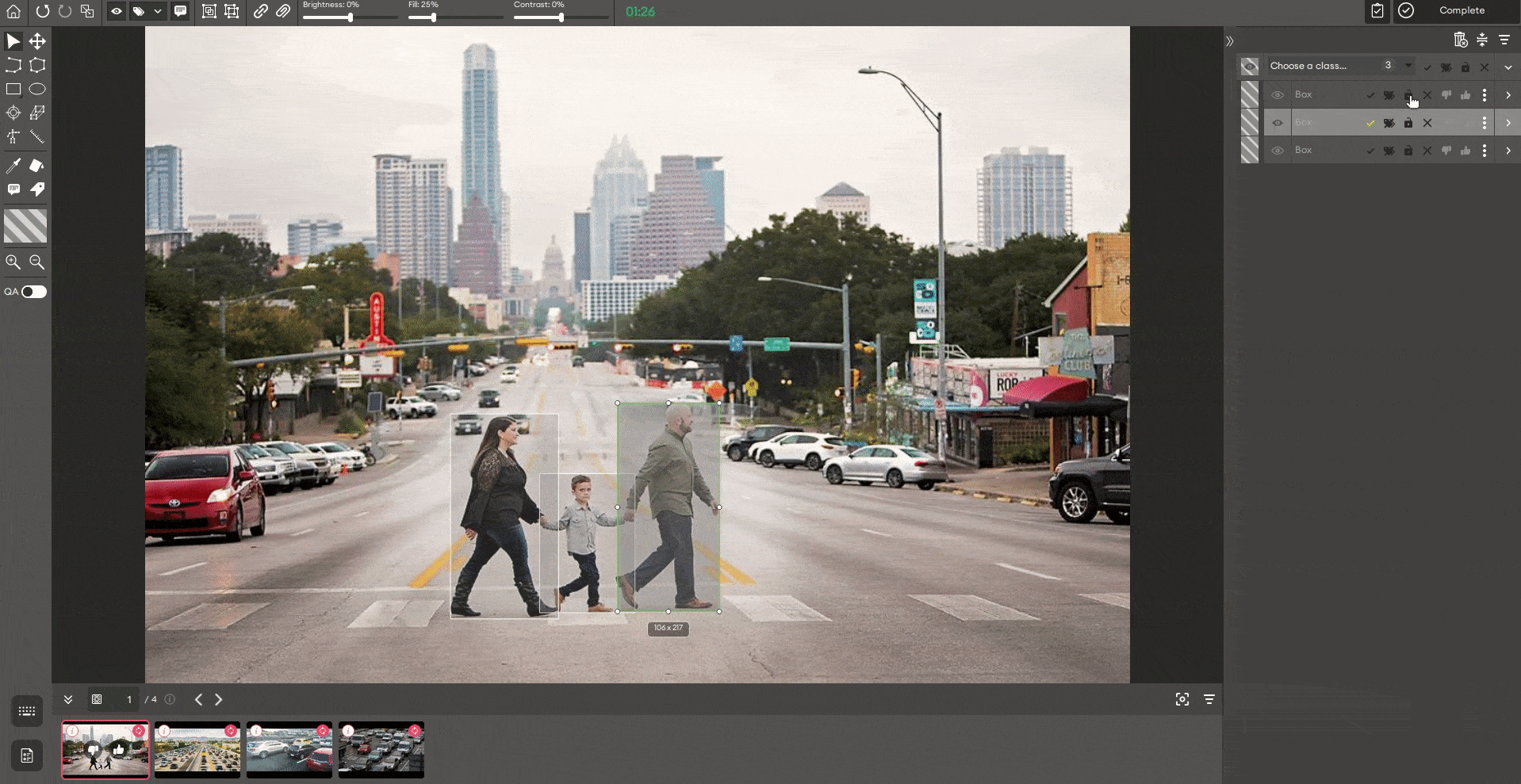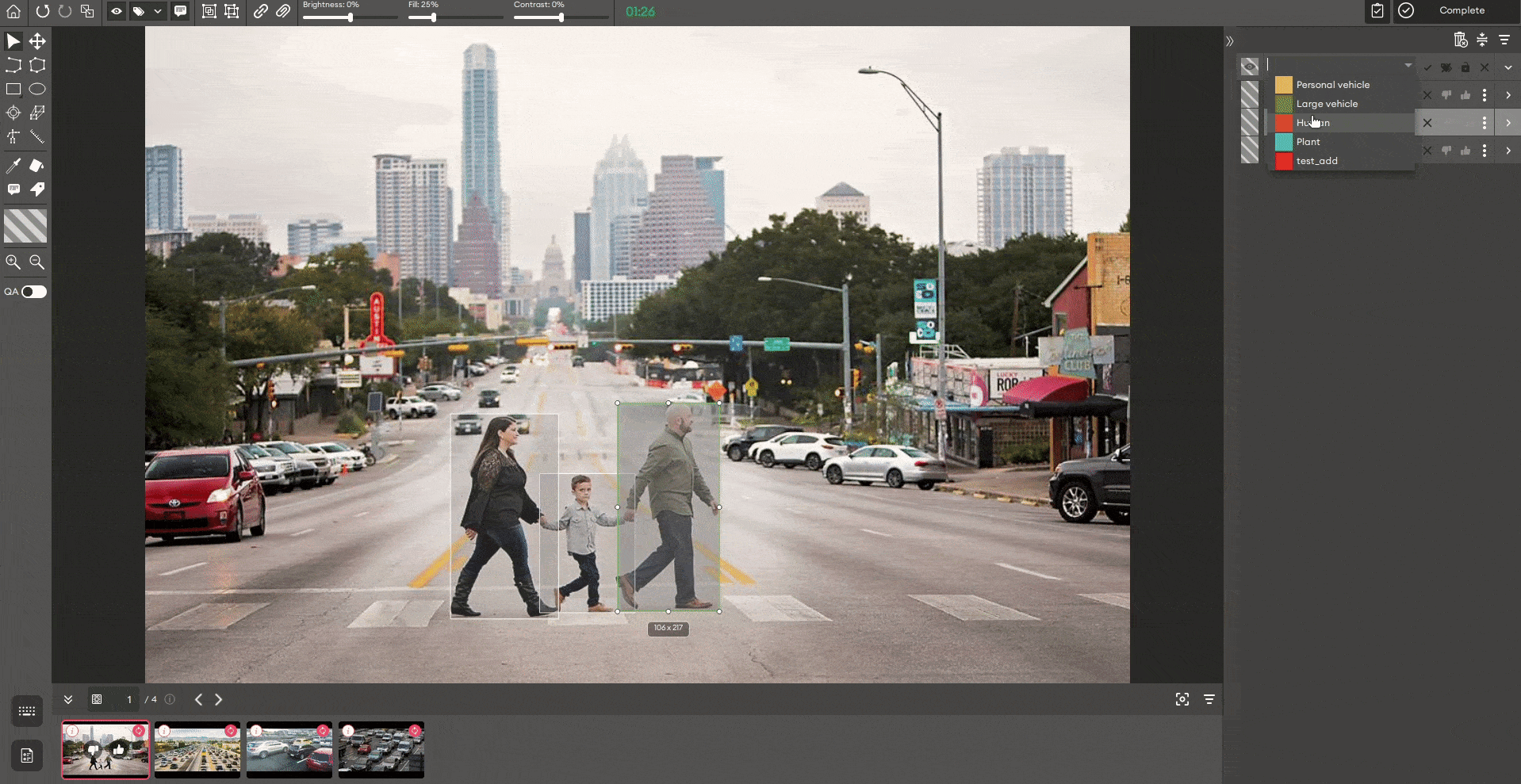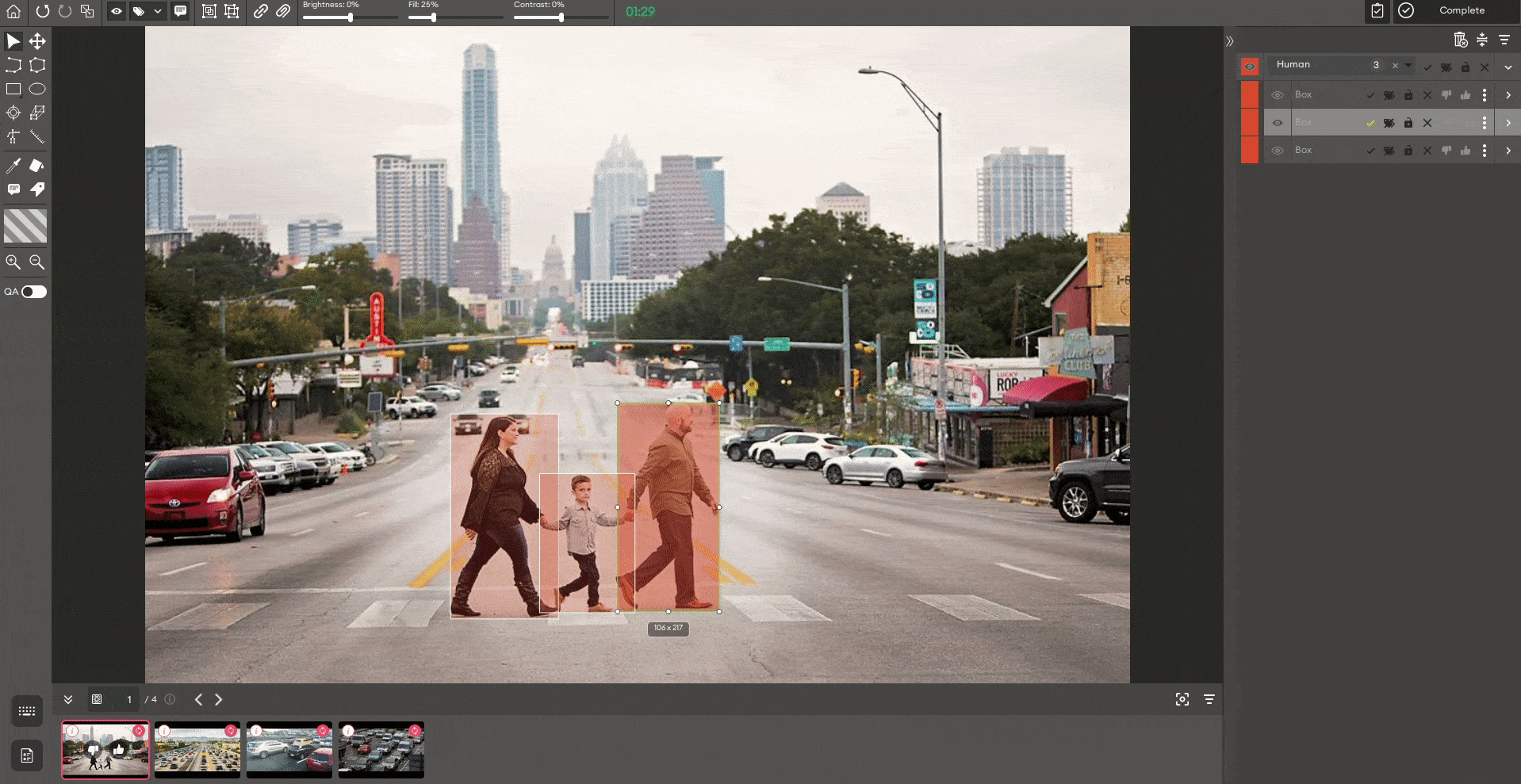
4) Choose the annotation task and one of the available pre-trained models.
5) Choose the projects and folders that contain the images you wish to train your model on.
6) Choose the projects and folders that contain the images you wish your model to be tested on.
7) Update some of the default hyper-parameters (optional).
8) Choose a GPU to train the new model on.
9) Click Run Training.

Among the six tasks that are described in the cocodataset.org, we provide pre-trained models for four of them:
- Instance segmentation
- Keypoint detection
- Object detection
- Semantic segmentation
Hyperparameters
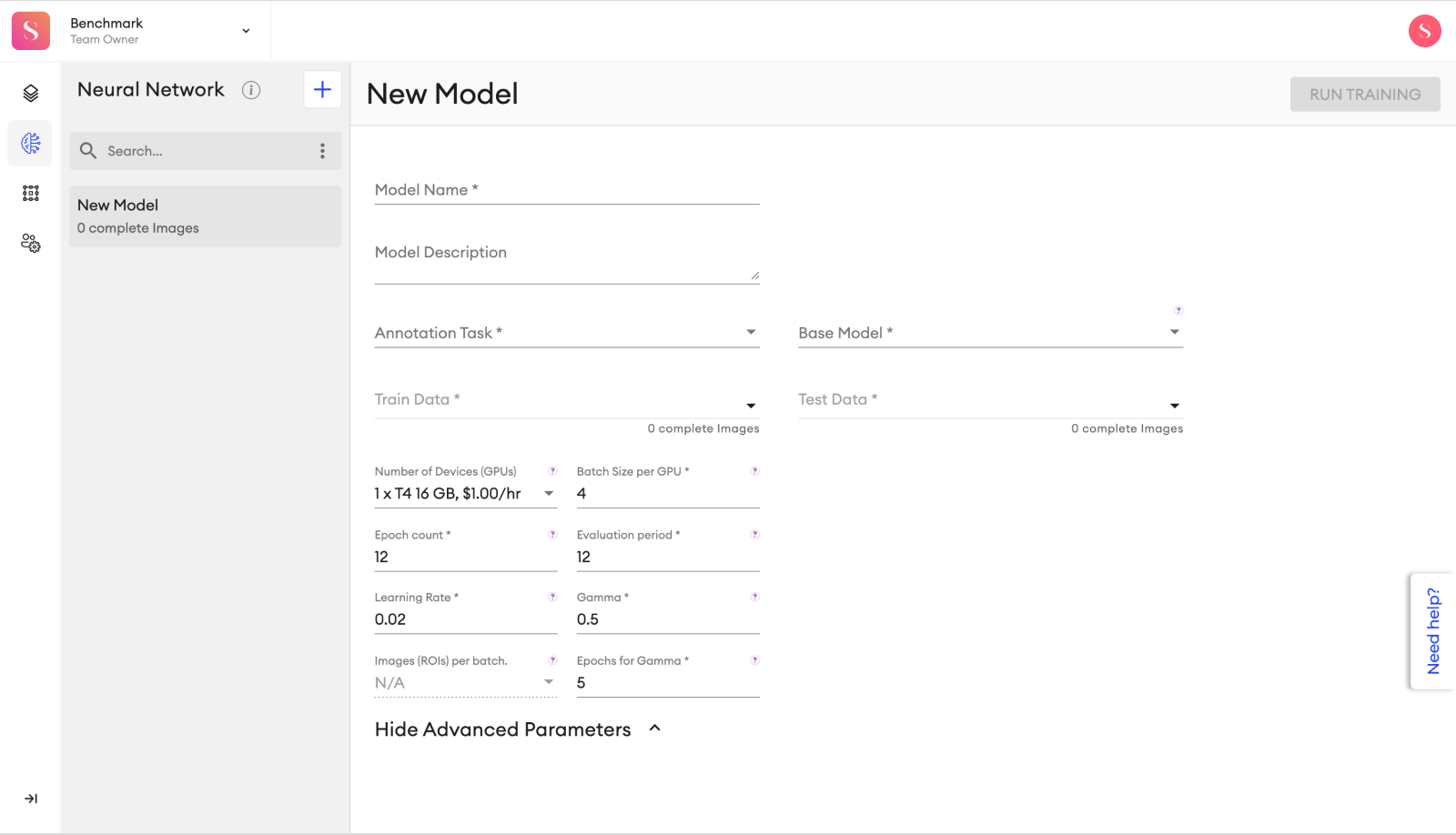
All available configurable fields for training a new Neural Network.
There are quite a few hyperparameters that can be tuned during the transfer learning process. If you have no idea what they mean, you can use the default hyperparameters as they will provide good learning for most of the use cases. The hyperparameters that we allow for fine-tuning are: Batch size (the number of images used in one iteration of the training procedure), epoch count, learning rate, gamma (the learning rate gets multiplied by this value after “Epochs for gamma” epochs), steps for gamma, images (RoIs) per batch (how many regions of interest to suggest per image), evaluation period (number of epochs after which a checkpoint of the model is saved, and the performance of the checkpoint is evaluated on the test set), train/test split ratio (we will use this percentage of images to train the new model).
The user can monitor the training process since we also provide training metrics. Note that if you change your mind after running the training, you can stop the training, and the learnings from the last epoch will be saved.
Testing newly trained network
Once the new NN model is trained with the given hyperparameters, it can be used to automate the annotation of the next set of images.
To see qualitatively how the new model performs, you need to run smart prediction using the newly trained model. A new model with the name that you have specified while running the training will appear in the dropdown list of possible NNs to choose from.

After we create a new model called New FineTuned Model using our NN functionality, it appears in the dropdown menu for the smart prediction.Once the smart prediction is over, you can view the results by clicking on the image and opening the annotation tool.
Using a fine-tuned model, one of our clients observed about 13% accuracy improvement over the original model when trying to annotate instances of the Person class.
Wrapping up
Automating the annotation process without writing a single line of code is essential for many computer vision engineers and annotation service providers. By using SuperAnnotate’s platform, we demonstrated a simple tutorial on how one can set up the automation process using transfer learning, and keep improving the annotation accuracy by annotating and training batches of images over and over again. Reach out at any moment if we can help you further.
Author: Vahagn Tumanyan, Computer Vision Engineer at SuperAnnotate






