
Due to the rapid development in AI, computer vision is being upgraded by improved versions of visual processing in images. Video annotation enables machines to detect and recognize moving objects through computer vision. The end result is later used to train machine learning (ML) and artificial intelligence (AI) models. In this day and age, video annotations are increasingly popular, given the progressive growth of the automotive sector. The algorithms fed by video annotations power vehicles with object detection and recognition, which is essential for cars to drive safely with little-to-no human intervention. Now, let’s dive into the fundamentals of video annotation in the order listed:
- What is video annotation?
- What is automatic video labeling?
- What is the purpose of video annotation in machine learning?
- How video annotation works: Best practices
- Challenges and critical considerations in video annotation
- Key takeaways
What is video annotation?
Video annotation is broadly defined as the task of labeling and tagging video footage to train a computer vision model. The difference between image and video annotations is that video annotation is processed through frame-by-frame image data. Annotating videos is more complicated and labor-intensive, as the target object is in motion. As such, a 20-second video is likely to consist of several hundred frames, which means it will take you a fair amount of time to complete a single video annotation project. Companies who are just stepping into CV cannot afford to invest too much time and human resources in a single project. That being said, they tend to outsource their annotation projects more often to streamline CV operations and develop a scalable pipeline.

What is automatic video labeling?
Automatic video labeling refers to using automated tools to label the target object in the footage. The labeled data is then used to train the ML model to detect objects in unlabeled video frames. The precision of the labeled data will determine your model performance, in the long run, stimulating faster scaling for your company. We’ll elaborate on the role of automation in video annotation in the following sections.
What is the purpose of video annotation in machine learning?
The purpose of video annotation is bound to its real-world applications. By going through the specifics of video annotation, we will cover the exact operations it is used for within the context of one of the major suppliers, the autonomous vehicle industry:
Object detection
The primary purpose of video annotation is to capture objects of interest to make them recognizable by the machines. A given ML model needs vast amounts of data to be able to mimic the human eye. So, the highest quality AI data variation is imperative to achieve the desired prediction accuracy.
Object localization
Video annotation is also applied for object localization, which can be explained as localizing the object that’s most visible and is dominant in an image. Besides, localization helps spot the boundaries in an image for vehicles to be aware of potential hazards on the roads.
Object tracking
Apart from object detection and localization, video annotations are used to track the traffic flow, cyclists on the streets, the differences in landscape, traffic lanes, and road signs. All these elements are essential for machines to drive independently and act upon the altering road dynamics while ensuring passenger safety.
Activity tracking
Similar to object tracking, navigating through human activity also contributes to a better perception of the environment and helps prevent accidents, even if those are initiated by unpredictable pedestrian behavior. The same is true for dogs, cats, and other animals crashing through the road unexpectedly. Every non-static object requires solid activity tracking and proper estimation of the movement to achieve maximum independence in driving.
To wrap up, video annotation covers every objective of self-driving cars. A model has to be able to recognize more objects per unit and meet safety standards so that vehicles receive approval for massive production.
How video annotation works: Best practices
There are multiple ways you could go with video annotations, including the single image method and the continuous frame method, which we’ll expand upon moving forward.
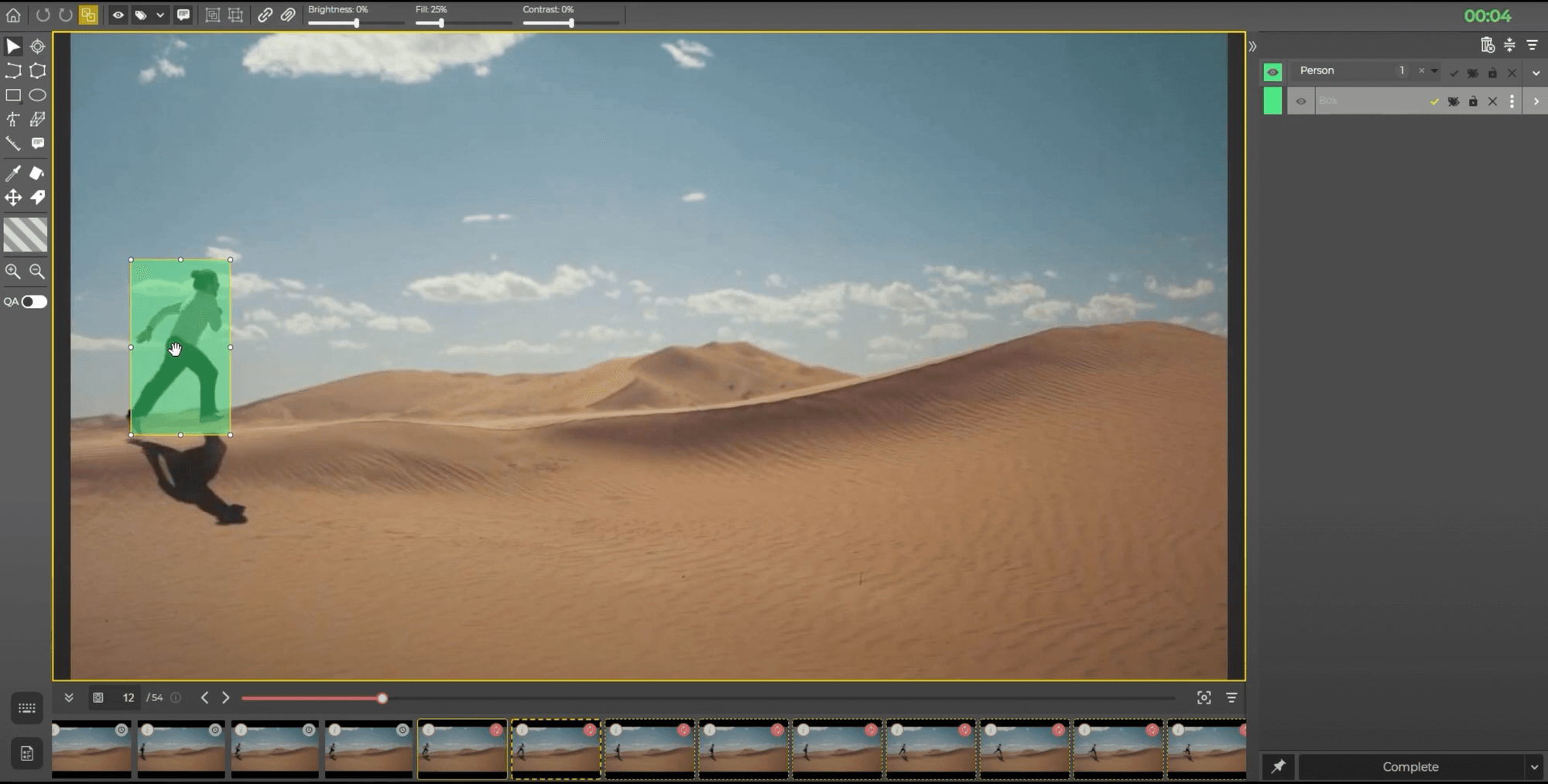
Single image technique
The single image method is the traditional image annotation, as the name suggests. You first extract images from the footage and annotate them one by one. And you might call me out on this, fairly enough, in that the single image method is not so efficient and is way outdated. This used to be the primary choice of the companies when annotation tools were not available.
In any case, with a single image method, companies are tasked with annotating an infinite number of frames, as average footage is likely to contain tens of thousands of images. There are too many pitfalls to consider, though, including the time that goes into annotating frames, the actual cost of the project, the probability of misclassified objects, annotation errors, and the opportunity cost. Think about it, is your effort worth the time put into completing the project, or you’d better take on several smaller projects instead? Of course, you may want to bring about the outsourced or crowdsourced services, but you are the one to decide whether outsourcing is relevant for your project.
Continuous frame technique
At present, the tedious task of video annotation is thankfully streamlined by the continuous frame methods. Here the computer automatically tracks moving objects, preserving consistent accuracy in dimensions. Optical flow is a continuous frame technique that analyzes the pixels in the preceding and succeeding frames and does pixel motion predictions of a respective frame.
The continuous frame method helps eliminate human bias, especially in case if the same objects leave and later reappear in an image. A model is more likely to identify that the object belongs to the same class, whereas human annotators can miss this out upon the lack of smooth and consistent communication. However, it’s not always that easy, and a handful of factors, including the image quality and resolution, can impact the image classification.

Challenges and critical considerations in video annotation
There are a few things to take into account when annotating video for your computer vision project:
- Annotation automation
Make sure you have at least some level of automation. You will have to deal with huge datasets, so embedded automation will be a great investment in your pipeline. Review your options carefully and select the toolset that suits your project requirements best.
- Consistency and accuracy
Maintaining consistency in labeling is truly challenging when it comes to video annotations. First, your target object moves, and you’ll have to capture every movement. Second, you have to make sure you track whether the leaving and reappearing objects have the same class, which is an extra hassle with multiple human annotators on board.
- Training and testing data
If there is a single overarching procedure in building a CV model, that is training and testing the model. Pay attention to the volume of the data too to avoid creating more room for error. If you want your model to make highly accurate predictions, be generous with what you feed into it. And if the model ends up generating more errors than expected, go back, increase the training and testing data, and retrain the model.
- Choosing the service provider
At this point, you probably realized that video annotation is hard to handle all alone, which makes outsourcing the task to service providers a popular choice among companies. SuperAnntotate provides a marketplace of annotation services where you can hire industry experts for top results.
Key takeaways
Models fueled by video annotations are well-versed in capturing greater contexts. A CV model delivers accurate results when it can also seamlessly catch objects in action. As you could expect, there are certain challenges that keep recurring depending on the project size and complexity. Most of them, however, concern annotation automation, consistency in data classification, effective management of the training data volume, selection of the right service provider, etc. These and other considerations should be at the forefront of your strategy to spruce up model deployment and achieve consistency in results. What did you find most challenging about video annotation? Don’t hesitate to reach out if you need more information.






